The NLP domain reports great advances to the extent that a number of problems, such as part-of-speech tagging, are considered to be fully solved. At the same time, such tasks as text summarization or machine dialog systems are notoriously hard to crack and remain open for the past decades.
However, if we look deeper into such tasks we’ll see that the problems behind them are rather similar and fall into two groups:
NLP is data-driven, but which kind of data and how much of it is not an easy question to answer. Scarce and unbalanced, as well as too heterogeneous data often reduce the effectiveness of NLP tools. However, in some areas obtaining more data will either entail more variability (think of adding new documents to a dataset), or is impossible (like getting more resources for low-resource languages). Besides, even if we have the necessary data, to define a problem or a task properly, you need to build datasets and develop evaluation procedures that are appropriate to measure our progress towards concrete goals.
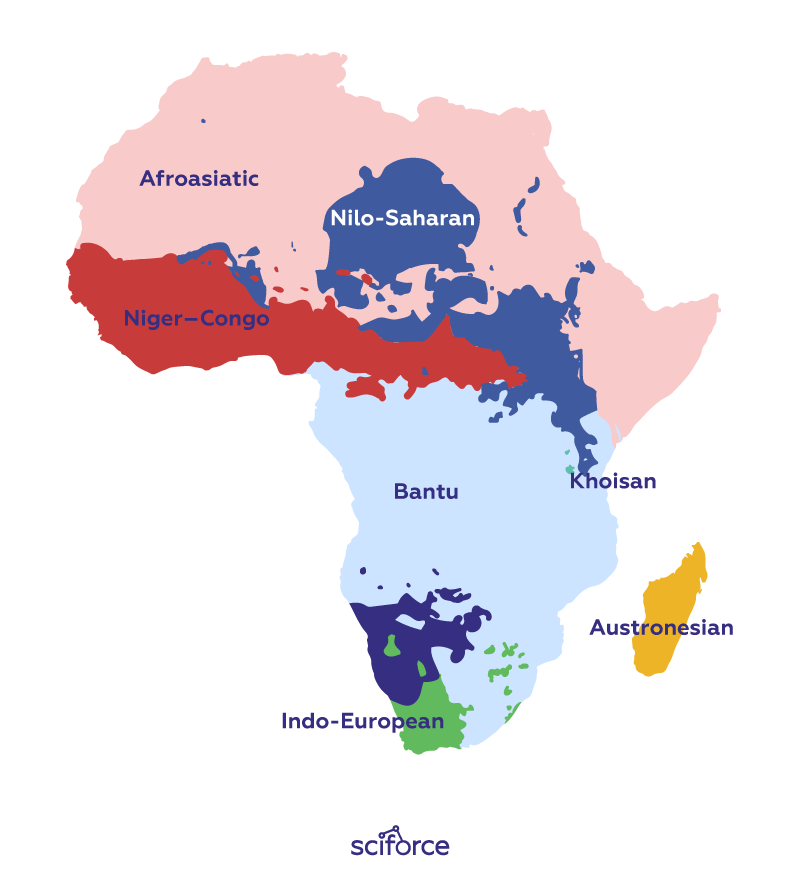
It is a known issue that while there are tons of data for popular languages, such as English or Chinese, there are thousands of languages that are spoken but few people and consequently receive far less attention. There are 1,250–2,100 languages in Africa alone, but the data for these languages are scarce. Besides, transferring tasks that require actual natural language understanding from high-resource to low-resource languages is still very challenging. The most promising approaches are cross-lingual Transformer language models and cross-lingual sentence embeddings that exploit universal commonalities between languages. However, such models are sample-efficient as they only require word translation pairs or even only monolingual data. With the development of cross-lingual datasets, such as XNLI, the development of stronger cross-lingual models should become easier.
Another big open problem is dealing with large or multiple documents, as current models are mostly based on recurrent neural networks, which cannot represent longer contexts well. Working with large contexts is closely related to NLU and requires scaling up current systems until they can read entire books and movie scripts. However, there are projects such as OpenAI Five that show that acquiring sufficient amounts of data might be the way out.
The second problem is that with large-scale or multiple documents, supervision is scarce and expensive to obtain. We can, of course, imagine a document-level unsupervised task that requires predicting the next paragraph or deciding which chapter comes next. However, this objective is likely to turn out too sample-inefficient. A more useful direction seems to be multi-document summarization and multi-document question answering.
https://openai.com/projects/five/
The problem of evaluation of language technology, especially such complex as dialogue, is often neglected, but it is an important point: we need both in-depth and thorough studies that shed light on why certain approaches work and others don’t and develop evaluation measures based on them. We need a new generation of evaluation datasets and tasks that show whether our techniques actually generalize across the true variety of human language.
Up to the present day, the problem of understanding the natural language remains the most critical for further making sense and processing of the text. The issues still unresolved include finding the meaning of a word or a word sense, determining scopes of quantifiers, finding referents of anaphora, the relation of modifiers to nouns and identifying the meaning of tenses to temporal objects. Representing and inferring world knowledge, and common knowledge in particular, is also difficult. Besides, there remain challenges in pragmatics: a single phrase may be used to inform, to mislead about a fact or speaker’s belief about it, to draw attention, to remind, to command, etc. The pragmatic interpretation seems to be open-ended — and difficult to be grasped by machines.
The main challenge of NLP is the understanding and modeling of elements within a variable context. In a natural language, words are unique but can have different meanings depending on the context resulting in ambiguity on the lexical, syntactic, and semantic levels. To solve this problem, NLP offers several methods, such as evaluating the context or introducing POS tagging, however, understanding the semantic meaning of the words in a phrase remains an open task.
Another key phenomenon of natural languages is the fact that we can express the same idea with different terms which are also dependent on the specific context: big and large can be synonyms when describing an object or a building but they are not interchangeable in all contexts, e.g. big can mean older, grown up in phrases like big sister; while large does not have this meaning and could not be substituted here. In NLP tasks, it is necessary to incorporate the knowledge of synonyms and different ways to name the same object or phenomenon, especially when it comes to high-level tasks mimicking human dialog.
The process of finding all expressions that refer to the same entity in a text is called coreference resolution. It is an important step for a lot of higher-level NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction. Notoriously difficult for NLP practitioners in the past decades, this problem has seen a revival with the introduction of cutting-edge deep-learning and reinforcement-learning techniques. At present, it is argued that coreference resolution may be instrumental in improving the performances of NLP neural architectures like RNN and LSTM.
Depending on the personality of the author or the speaker, their intention and emotions, they might also use different styles to express the same idea. Some of them (such as irony or sarcasm) may convey a meaning that is opposite to the literal one. Even though sentiment analysis has seen big progress in recent years, the correct understanding of the pragmatics of the text remains an open task.
The good news is that NLP has made a huge leap from the periphery of machine learning to the forefront of the technology, meaning more attention to language and speech processing, faster pace of advancing and more innovation. The marriage of NLP techniques with Deep Learning has started to yield results — and can become the solution for the open problems. It will just take some time.