
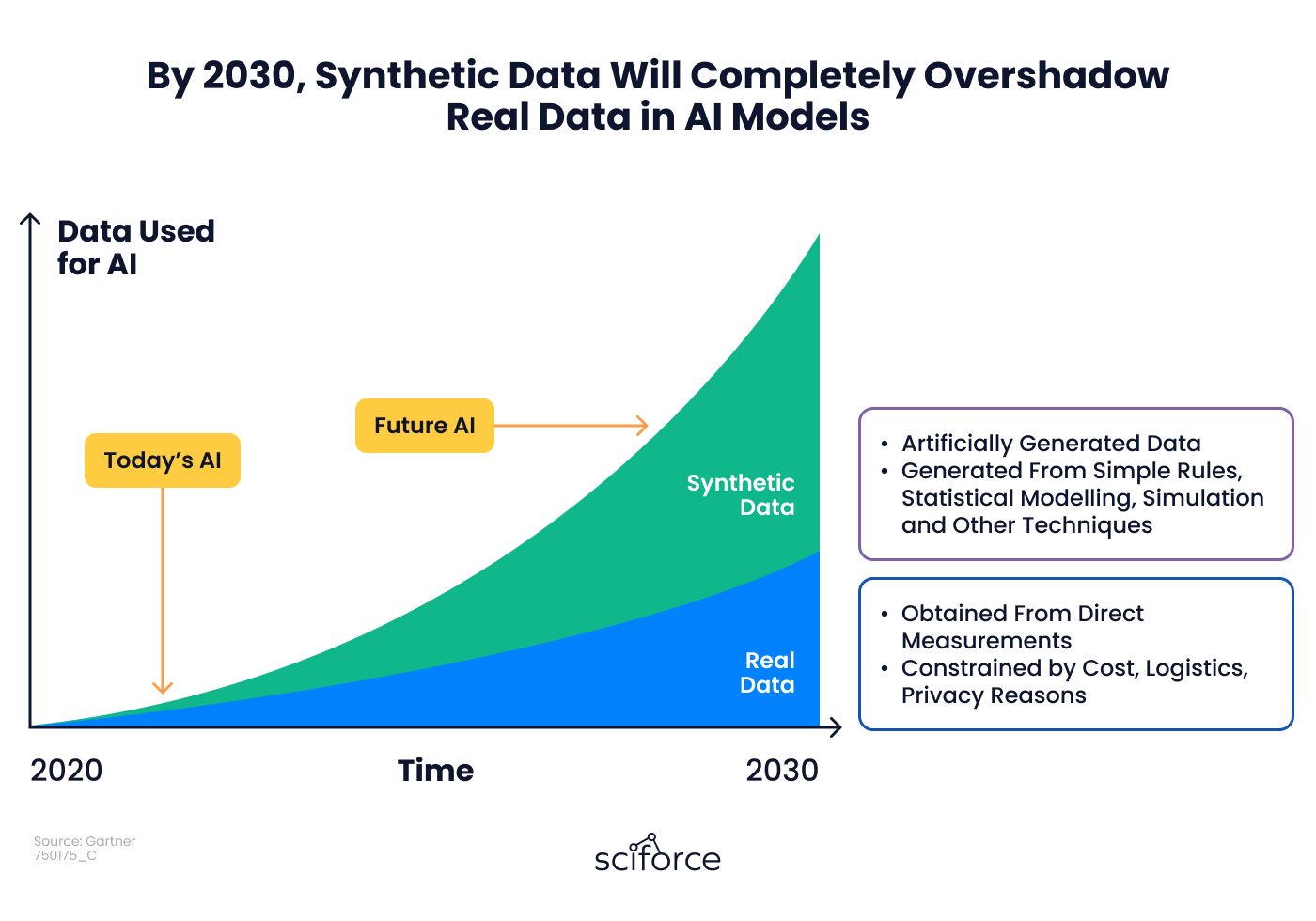
What if businesses could access unlimited, high-quality data without privacy risks or tedious preparation? Synthetic data is making this possible, offering a scalable, efficient alternative to real-world data. Gartner predicts synthetic data will surpass real data in AI model training by 2030, with the market growing from $351.2 million in 2023 to USD 2,339.8 million by 2030, at a CAGR of 31.1%.
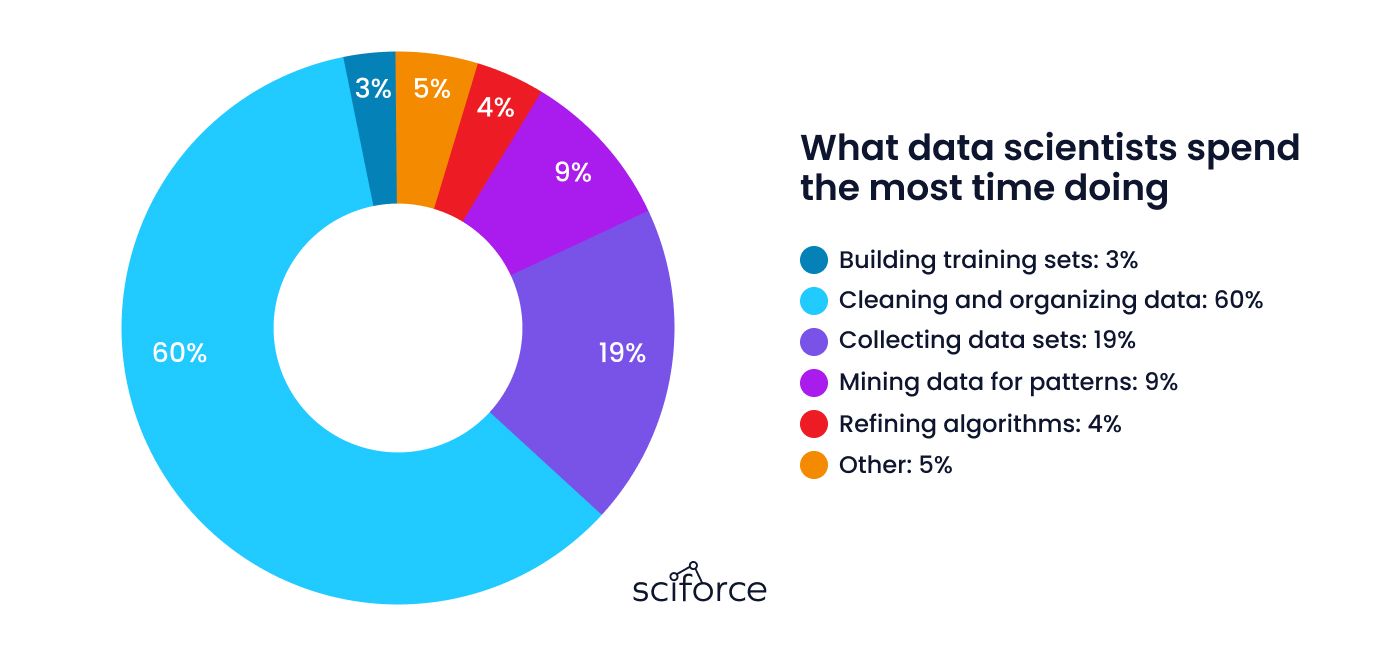
Data preparation is a major hurdle, with data scientists spending over 60% of their time cleaning and organizing data. Synthetic data addresses this by providing ready-to-use, privacy-safe datasets that save time, cut costs, and avoid reliance on sensitive information.
As industries like healthcare, finance, and retail face growing data needs, synthetic data is helping businesses innovate faster and make smarter decisions. This article explores its potential, benefits, and applications.
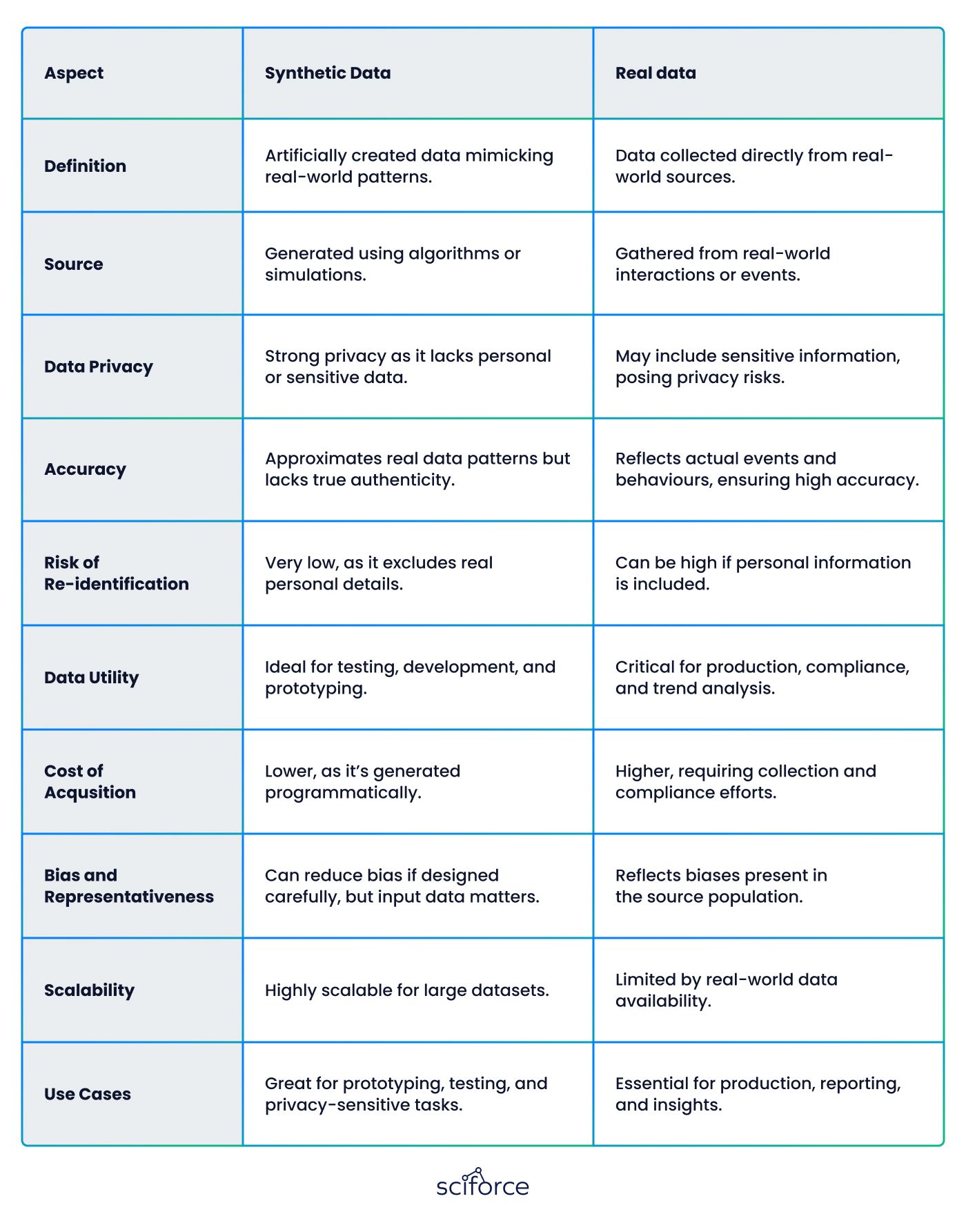
Synthetic data is data created by computers to imitate the characteristics and patterns of real-world data, without copying any actual records or personal information. Using algorithms and machine learning, synthetic data can take various forms, such as images, text, or numbers, and is designed to represent different types of information and behaviors.
Synthetic data is changing the way industries work with data by providing a scalable, privacy-safe alternative to real-world information. It replicates real data patterns, allowing organizations to test systems, train AI models, and simulate scenarios that are often difficult to capture with real data. Here are some of the practical and impactful ways of synthetic data usage:
AI Model Training
Synthetic data offers a scalable solution for creating balanced and diverse training datasets, which helps improve model accuracy and reduce bias. By replicating the structure and patterns of real data, synthetic data allows teams to simulate rare scenarios and make adjustments during training.
Software Testing and Development
Synthetic data helps developers safely simulate user interactions without using real data. In mobile banking, it mimics transactions and payments to test security and functionality. For e-commerce, it replicates shopping behaviors and purchase histories, ensuring a realistic user experience.
Healthcare and Life Sciences
In healthcare, synthetic data lets researchers work with realistic, patient-like information while protecting privacy. For instance, synthetic medical records can represent conditions like heart disease, diabetes, or cancer, making it possible to develop and test diagnostic tools and predictive health models.
Financial Services
In finance, synthetic data enables secure model development for fraud detection, risk assessment, and analytics without exposing real client data. For example, JPMorgan uses synthetic data sandboxes to simulate realistic financial scenarios, such as transaction patterns and account activities, while protecting privacy. Synthetic data also models rare events like market crashes or complex fraud patterns, helping improve model performance and speed up development.
Telecommunications
Companies like Telefónica use synthetic data to analyze user behaviors, such as call patterns, data usage, and service preferences, while ensuring privacy compliance. This data allows for in-depth analysis of customer interactions, network optimization, predicting peak usage, and tailoring services based on usage trends without exposing real customer information.
Retail analytics
In retail, synthetic data helps analyze customer preferences, such as shopping habits and seasonal demand, while protecting privacy. For example, Walmart uses it to simulate buying patterns, optimize inventory, forecast demand, and test new products or pricing strategies seeing how customers might respond without using actual customer data.
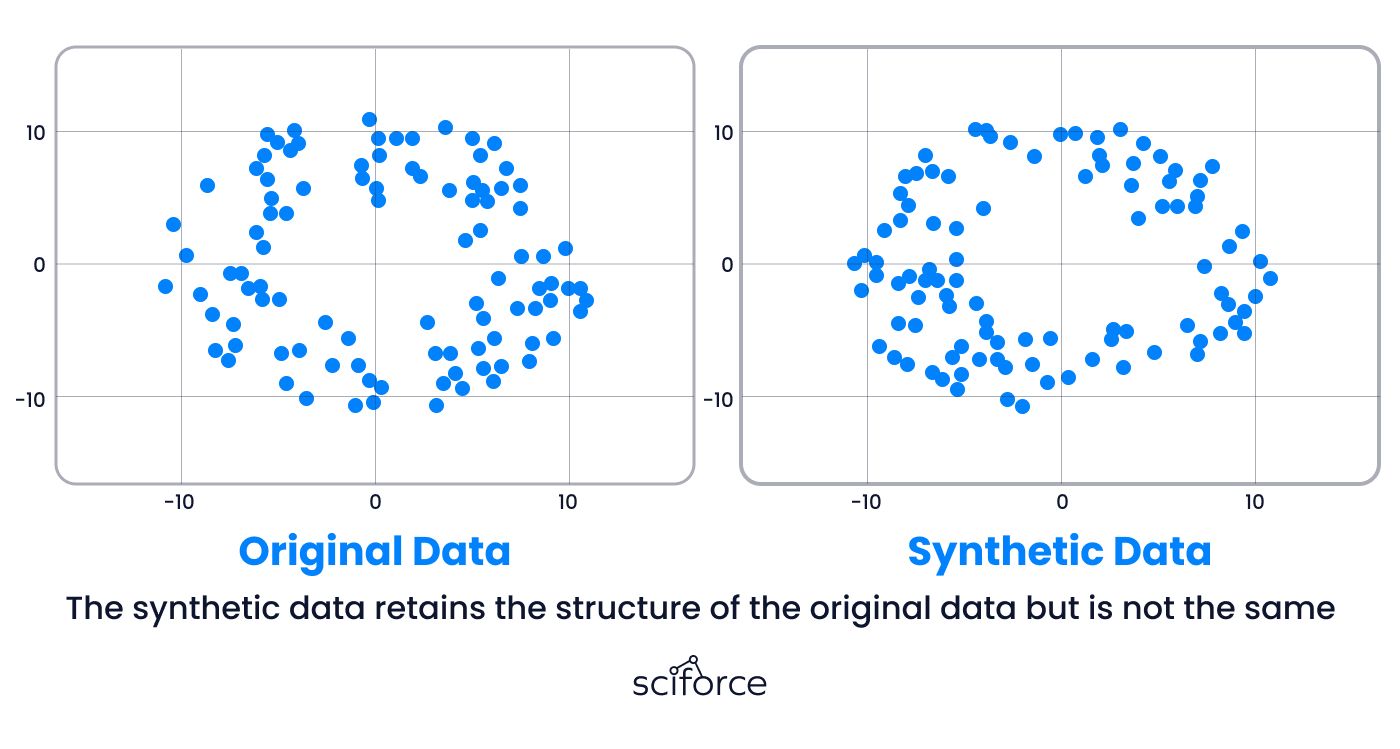
Synthetic data isn’t just about mimicking reality—it’s about creating tailored datasets that solve real problems when actual data isn’t enough. Whether it’s creating detailed medical images for diagnostics or simulating complex interactions for AI training, these techniques are designed to address gaps in real data with precision and scalability. Here’s a closer look at the methods powering synthetic data creation and their applications:
Generative Adversarial Networks (GANs):
Two neural networks (generator and discriminator) work together to create realistic data:
Variational Autoencoders (VAEs):
Use an encoder-decoder setup to generate diverse yet realistic data:
Agent-Based Modeling:
Agent-based modeling lets "agents," like vehicles, people, or robots, act independently by following set rules and responding to their surroundings:
Validation ensures synthetic data is accurate, unbiased, and reliable:
Synthetic data tools create realistic datasets tailored to industry needs while ensuring privacy. With features like customizable settings and templates, these tools simplify tasks such as AI model training, software testing, and analytics. Here are some commonly used tools and their applications:
- Synthea™:
An open-source synthetic patient generator that creates detailed medical records mirroring real patient histories, including conditions like heart disease, diabetes, and cancer. It generates data across all healthcare aspects, from medications and allergies to social determinants of health. By simulating realistic patient conditions and treatment responses, Synthea supports healthcare testing, predictive modeling, and drug discovery, enabling researchers to safely explore outcomes and side effects.
- Hazy:
A tool designed for business and finance, Hazy generates realistic synthetic datasets for tasks like risk modeling, credit scoring, and customer analytics. It ensures sensitive business data is protected while enabling secure analysis and machine learning.
- Datagen:
A tool for computer vision that generates realistic image data, such as faces and environments, to train AI models for tasks like facial recognition, robotics, and augmented reality. It can simulate detailed conditions, like different lighting or expressions, to improve model performance.
These tools streamline synthetic data creation with customizable features and templates, enabling quick generation of industry-specific datasets for tasks like medical testing, fraud detection, and AI training, while ensuring privacy and security compliance.
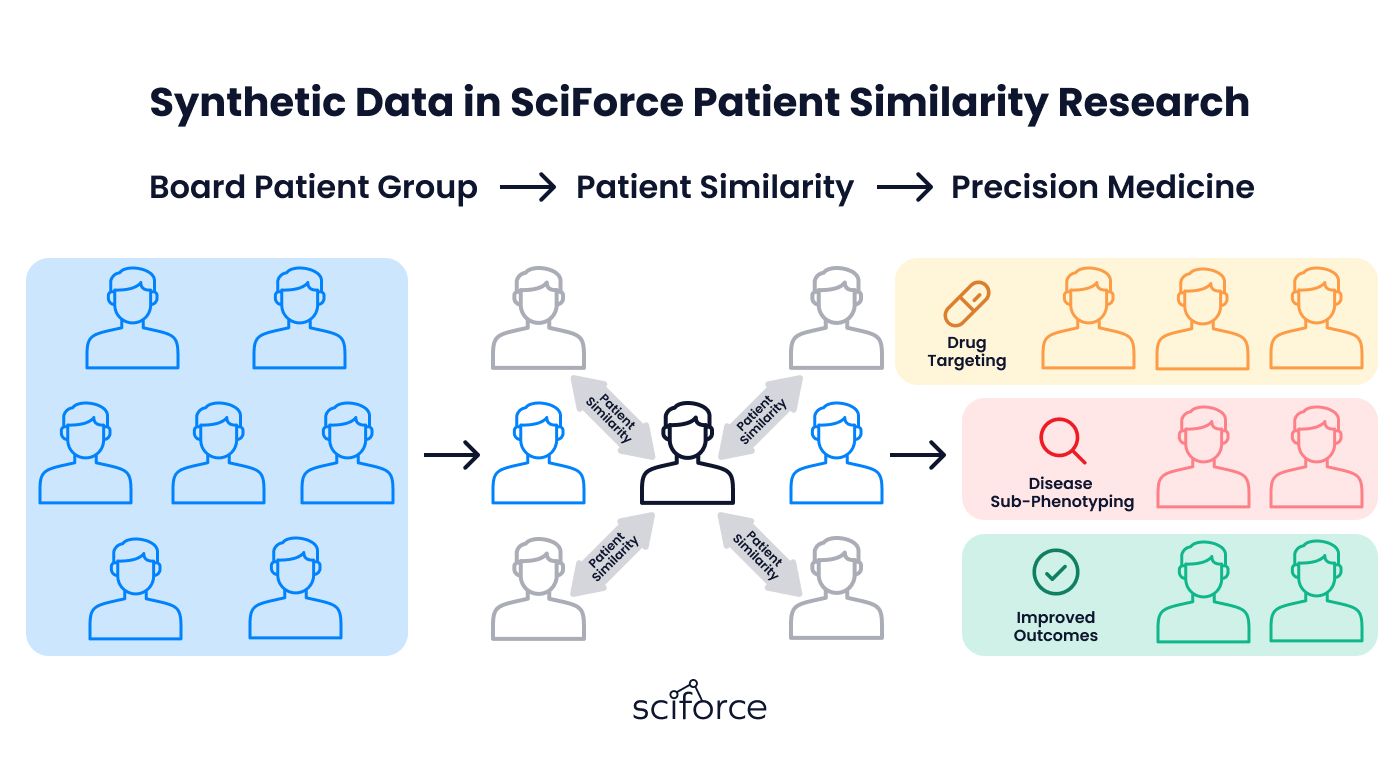
How can oncology patients be grouped by similar disease patterns and treatments without risking privacy? SciForce addressed this by using machine learning and synthetic data to create advanced algorithms, showing how AI can support personalized care and smarter healthcare solutions.
Our research focused on finding similarities between oncology patients using machine learning and synthetic data. We analyzed key medical details, such as:
Medical Histories: Diagnoses, how diseases developed, and treatment details.
Biological Traits: Lab results and clinical markers showing a patient’s condition or treatment response.
Demographics: Factors like age or gender, included only when relevant, such as in gender-specific cancers.
Synthetic data was essential in the early stages, enabling rapid testing, experimentation, and refinement without the ethical and regulatory challenges of real-world patient data.
Our research was designed to use synthetic data and machine learning to create a scalable solution for grouping oncology patients with similar medical profiles. Here’s how we approached it:
Data Preparation:
We worked with a synthetic dataset that included various cancer types and patient scenarios. Key features like diagnoses, disease progression, treatment responses, and clinical markers were chosen to focus on real-world healthcare needs.
Algorithm Development and Testing:
We developed and tested machine learning algorithms to group patients based on shared medical patterns. The synthetic data provided a safe environment to test and improve our methods without risking patient privacy.
Refining the Approach:
By focusing on key factors like cancer stage and treatment outcomes, we refined our algorithms to make them more accurate and clinically relevant. The synthetic environment also helped us identify challenges, like selecting the most important features and ensuring scalability.
Validation and Future Use:
We validated our algorithms using synthetic data, demonstrating their potential for applications like personalized treatment planning, predictive modeling, and patient grouping. The research also showed the importance of using real-world data to further improve and deploy the solution.
1. Algorithm Development:
2. Demonstrated Applications:
3. Impact for Healthcare:
This research showed how synthetic data and machine learning can bring new solutions to oncology care. By accurately grouping similar patients and highlighting applications like personalized treatments and predictive tools, it provides a solid starting point for future healthcare advancements.
Synthetic data isn’t just reshaping industries - it’s redefining possibilities. By providing secure, scalable, and flexible datasets, it empowers organizations to solve challenges, unlock innovation, and achieve goals that once seemed out of reach.
At SciForce, we’ve seen firsthand how synthetic data can turn ambitious ideas into reality, from advancing healthcare research to optimizing AI models. If you’re ready to harness the potential of synthetic data and transform your business, we’re here to help.
Let’s make it happen - contact us today for a free consultation and start building smarter solutions with synthetic data.


