
GitHub and OpenAI presented a new code-generating tool, Copilot, that is now a part of Visual Studio Code that is autocompleting code snippets. Copilot is based on Codex that is a product of GPT-3, presented a year ago. It seems like the hype around GPT-3 still is not going to evaporate, and we decided to delve into details step-by-step. Check it out.
GPT-3 stands for Generative Pre-trained Transformer 3, and it is the third version of the language model that Open AI released in May 2020. It is generative, as GPT-3 can generate long sentences of the unique text as the output. Notice that most neural networks are capable only of spitting out yes or no answers or simple sentences. Pre-trained means that the language model has not been built with any special domain knowledge, but it can complete domain-specific tasks like translation. Thus, GPT-3 is the most innovative language model that has ever existed.
Ok, but what is Transformer, then? Simply put, it is the neural network’s architecture developed by Google’s scientists in 2017, and it uses a self-attention mechanism that is a good fit for language understanding. Given that the attention mechanism enabled a breakthrough in the NLP domain in 2015, Transformer became a ground for GPT-1 and Google’s BERT, another great language model. In essence, attention is a function that calculates the probability of the next word appearing, surrounded by the other ones. By the way, we have developed an explainer for BERT.
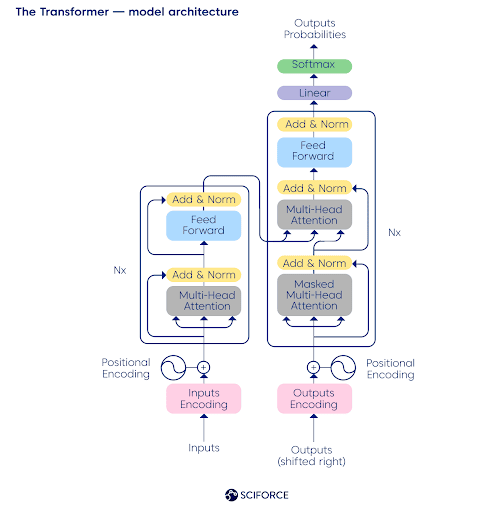
Wait, but what makes GPT-3 so unique? GPT-3 language model has 175 billion parameters, i.e., values that a neural network is optimizing during the training (compare with 1,5 billion parameters of GPT-2). Thus, this language model has excellent potential for automatization across various industries — from customer service to documentation generation. You could play around with the beta of GPT-3 Playground by yourself.
How can I use GPT-3 for my applications? As of July 2021, you can join the waitlist since the company can offer a private beta version of its API under the LmaS basis (language-model-as-a-service).
Here are the examples that you might have already heard of — GPT-3 is writing stunning fiction. Gwern, author of the gwern.net who is experimenting both with GPT-2 and GPT-3, states that “GPT-3, however, is not merely a quantitative tweak yielding “GPT-2 but better” — it is qualitatively different.” The beauty of GPT-3 for text generation is that you need to train anything in a usual way. Instead, it would be best to write the prompts for GPT-3 to teach it anything you want.
Sharif Shameem used GPT-3 for debuild, a platform that generates code as per request. You could type the request like “create a watermelon-style button” and grab your code to use for an app. You could even use GPT-3 to generate substantial business guidelines, as @zebulgar did.
Let us look under the hood and define the nuts and bolts of GPT-3.
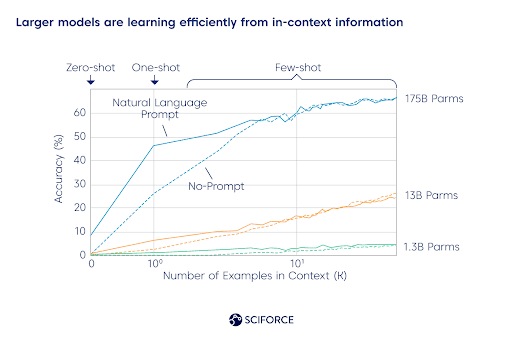 Larger models are learning efficiently from in-context information
Larger models are learning efficiently from in-context information
To put it bluntly, GPT-3 calculates how likely some word can appear in the text given the other one in this text. It is known as the conditional probability of words. For example, the word chair in the sentences: “Margaret is arranging a garage sale... Maybe we could buy that old ___ “ is much more likely to appear than, let us say, an elephant. That means the probability of a word chair occurring in the prompted text is higher than the probability of an elephant.
GPT-3 uses some form of data compression while consuming millions of sample texts to convert the words into vectors, i.e., numeric representations. Later, the language model is unpacking the compressed text in human-friendly sentences. Thus, compressing and decompressing text develops the model’s accuracy while calculating the conditional probability of words.
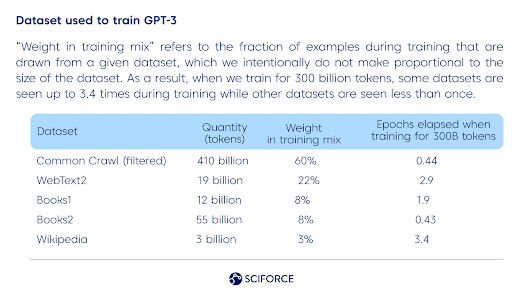 Dataset used to train GPT-3
Dataset used to train GPT-3
Since GPT-3 is high-performing in the “few-shot” settings, it can respond in a way consistent with a given example piece of text that has never been exposed before. Thus, it only needs a few examples to produce a relevant response, as it has already been trained on lots of text samples. Check out the research paper for more technical details: Language Models are Few-Shot Learners.
 The few-shot model needs only a few examples to produce a relevant response, as it has already been trained on lots of text samples. The scheme illustrates the mechanics of English to French translation.
The few-shot model needs only a few examples to produce a relevant response, as it has already been trained on lots of text samples. The scheme illustrates the mechanics of English to French translation.
After the training, when the language model’s conditional probability as accurate as possible, it can predict the next word while given an input word, sentence, or a fragment as a prompt. Speaking formally, prediction of the next word relates to the natural language inference.
In essence, GPT-3 is a text predictor — its output is a statistically plausible response to the given input, grounded on the data it was trained before. However, some critiques arguing that GPT-3 is not the best AI system for question answering and text summarizing. GPT-3 is mediocre compared to the SOTA (state-of-the-art) methods per each NLP task separately, but it is much more general than any previous system, and the upcoming ones will be resembling GPT-3. In general, GPT-3 can perform NLP tasks after a few prompts are given. It demonstrated high performance under the few-shot settings in the following tasks:
GPT-3 demonstrated a perplexity of 20,5 (defines how well a probability language model predicts a sample) under the zero-shot circumstances on the Penn Tree Bank (PTB). The closest rival, BERT-Large-CAS, boasts of 31,3.
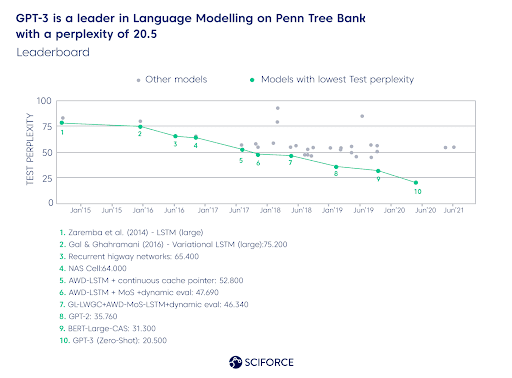 GPT-3 is a leader in Language Modelling on Penn Tree Bank with a perplexity of 20.5
GPT-3 is a leader in Language Modelling on Penn Tree Bank with a perplexity of 20.5
GPT-3 also demonstrates 86,4% accuracy (an 18% increase from previous SOTA models) in the few-shot settings while performing the LAMBADA dataset test. For this test, the model predicts the last word in the sentence, requiring “reading” of the whole paragraph. Important notice: GPT-3 demonstrated these results thanks to the fill-in-the-blank examples like: George bought some baseball equipment, a ball, a glove, and a_____. →”
Moreover, researchers report about 79,3% accuracy while picking the best ending of a story while on the HellaSwag dataset in the few-shot settings. And it demonstrated 87,7% accuracy on the StoryCloze 2016 dataset (which is still “4.1% lower than the fine-tuned SOTA using a BERT based model”).
… or testing broad factual knowledge with GPT-3. As per the GPT-3 research paper, it was tested on Natural Questions, WebQuestions, and TriviaQA datasets, and the results are the following:
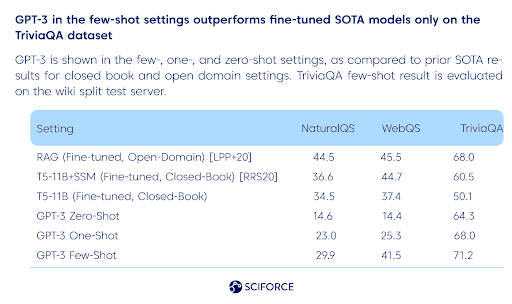 GPT-3 in the few-shot settings outperforms fine-tuned SOTA models only on the TriviaQA dataset
GPT-3 in the few-shot settings outperforms fine-tuned SOTA models only on the TriviaQA dataset
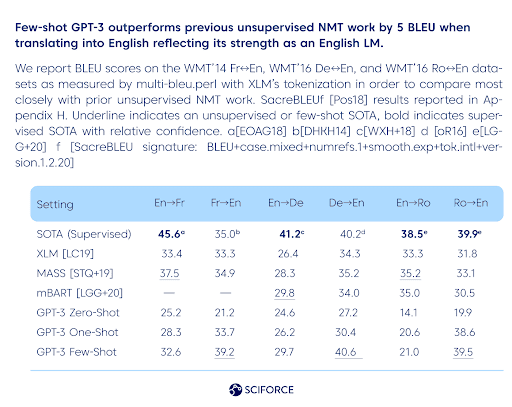
As for translation, supervised SOTA neural machine translation (NMT) models are the clear leaders in this domain. However, GPT-3 reflects its strength as an English LM, mainly when translating into English. Researchers also state that “GPT-3 significantly outperforms prior unsupervised NMT work when translating into English but underperforms when translating in the other direction.” In general, across all three language models tested (English in combinations with French, German, and Romanian), there is a smooth upward trend with model capacity:
Winograd-style tasks are classical NLP tasks, determining word pronoun referring in the sentence when it is grammatically ambiguous but semantically unambiguous for a human. Fine-tuned methods have recently reached human-like performance on the Winograd dataset but still lag behind the more complex Winogrande dataset. GPT-3 results are the following: “On Winograd GPT-3 achieves 88.3%, 89.7%, and 88.6% in the zero-shot, one-shot, and few-shot settings, showing no clear in-context learning but in all cases achieving strong results just a few points below state-of-the-art and estimated human performance. ”
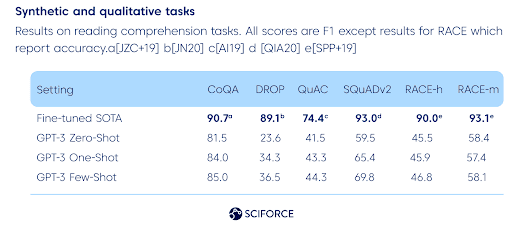
As for physical or scientific reasoning, GPT-3 is not outperforming fine-tuned SOTA methods:
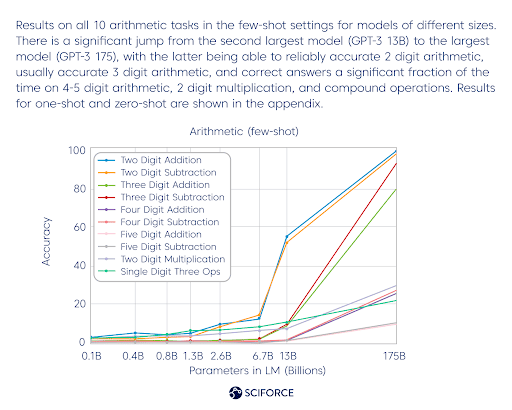
GPT-3 is not that good at arithmetic still, since the results are the following:
However, when it comes to the news article generation, human detection of GPT-3 written news (few-shot settings) is close to chance — 52% of mean accuracy.
Well, even the Open AI CEO Sam Altman tweeted that GPT-3 is overhyped, and here is what the researchers themselves state:
GPT-3 is not good at text synthesis — while the overall quality of the generated text is high, it starts repeating itself at the document level or when it goes to the long passages. It is also lagging at the domain of the discrete language tasks, having difficulty within “common sense physics”. Thus, it is hard for GPT-3 to answer the question: “If I put cheese into the fridge, will it melt?” GPT-3 has some notable gaps in reading comprehension and comparison tasks.
Tasks that empirically benefit from bidirectionally are also areas of improvement for GPT-3. It may include the following: “fill-in-the-blank tasks, tasks that involve looking back and comparing two pieces of content, or tasks that require re-reading or carefully considering a long passage and then generating a very short answer,” as researchers state.
Models like GPT-3 have a lot of skills and become “overqualified” for some specific tasks. Moreover, it is the computing-power hungry model: “training the GPT-3v175B consumed several thousand petaflop/s-days of compute during pre-training, compared to tens of petaflop/s-days for a 1.5B parameter GPT-2 model”, as researchers state.
Since the model was trained on the content that humans generated on the internet, there are still troubles referring to bias, fairness, and representation. Thus, GPT-3 can generate prejudiced or stereotyped content. But you may already read a lot about it online, or you can check it out in the research paper. The authors are dwelling on it pretty well.
GPT-3 is a glimpse of the bright future in NLP, helping to generate code, meaningful pieces of texts, translation, and doing well with different tasks. Also, it has its limitations and ethical issues like generating biased fragments of text. All in all, we are witnessing something interesting, as it always used to be in NLP.
Clap for this blog and give some more inspiration to us.
Check out more of our posts on NLP:
Text Preprocessing for NLP and Machine Learning Tasks
Biggest Open Problems in Natural Language Processing
A Comprehensive Guide to Natural Language Generation
NLP vs. NLU: from Understanding a Language to Its Processing