
The client works in the Financial Technology (FinTech) sector, focusing on digital invoicing and data management for transportation services. They act as a middleman offering technical solutions to taxi services, helping them manage invoices more efficiently and keeping their financial records well-organized.
They help turn physical taxi receipts into a standardized digital format, dealing with various receipt types and photo qualities.
Client's key challenge is dealing with receipts in different formats from various taxi services and turning a poor photo of a receipt into a clear image to understand and extract the data from.
Variability of Data
Taxi receipts came in numerous formats with unique layouts, languages, and structures. Some receipts had items listed horizontally, while others used vertical columns. Additionally, the language used in receipts varied by country, and certain fields were formatted differently (e.g., date formats, currency symbols). In our case, we had to work with receipts in Swedish and English.
Poor Photo Quality
Photos of receipts often have issues such as low resolution, poor lighting, blurriness, and visual artifacts like shadows and reflections. Additionally, most receipt photos are taken at an angle, making it harder to recognize the values.
Data Accuracy
Ensuring that the extracted data from receipts was accurate and reliable for tracking expenses, despite differences in receipt layouts, inconsistent field formats (such as dates and prices), language variations, low-quality photos.
Model Training Resources
Training large models like LLMs required significant computational resources, including high-performance GPUs, extensive memory, and long training times, making it costly and time-consuming.
Integration and Scalability
Integrating the processed receipt data into existing financial and management systems, and scaling the solution to handle large volumes of receipts, potentially reaching millions per month.
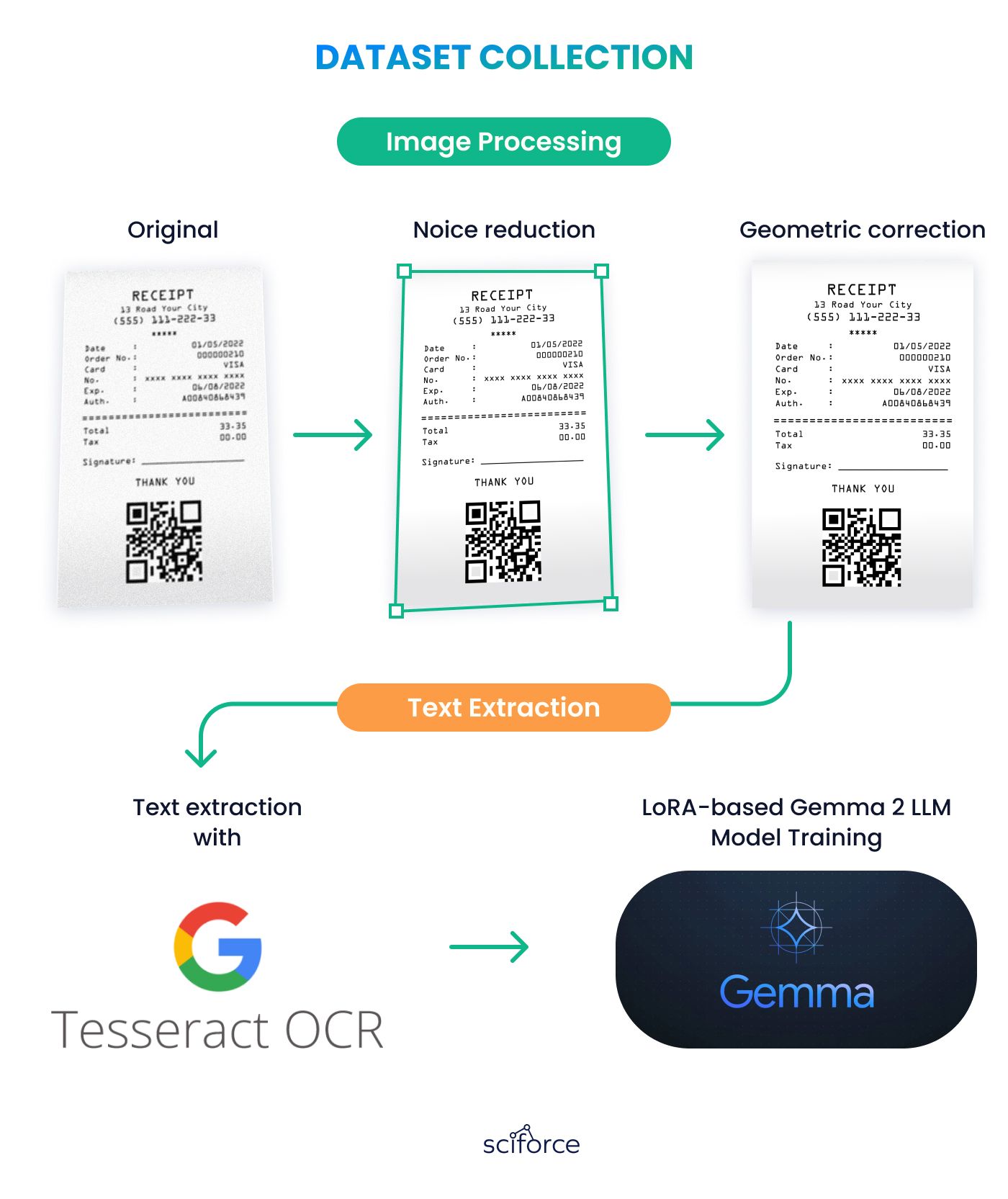
Dataset Сollection
We collected a dataset around 10.000 receipts that included a wide range of receipt formats in English and Swedish languages. It was used to train the model models to recognize and adapt to these variations, ensuring accurate processing.
Image Enhancement
Implemented advanced image enhancement techniques, including noise reduction and upsampling with GANs, to improve image quality before processing.
Accurate Text Extraction
Used OCR technology like Tesseract and trained LLMs to improve text extraction and classification accuracy. Implemented post-processing steps to correct errors and maintain data integrity.
Model Training
Employed LoRA-based training to focus on a small portion of the model's weights, optimizing resource usage while maintaining high accuracy.
Data Integration
Choose relational databases for structured data storage and seamless integration with existing systems, allowing for efficient data retrieval and manipulation.
Image Enhancement
Enhances the quality of receipt images by reducing noise and performing upsampling using Generative Adversarial Networks (GANs). This also includes geometric transformations to make the receipts easy to read, as if they were scanned.
Invoice Detection
Trains a model to accurately detect and delineate the boundaries of receipts, ensuring that only relevant information is captured. Utilizes a dataset with labeled check boundaries, trained using YOLO.
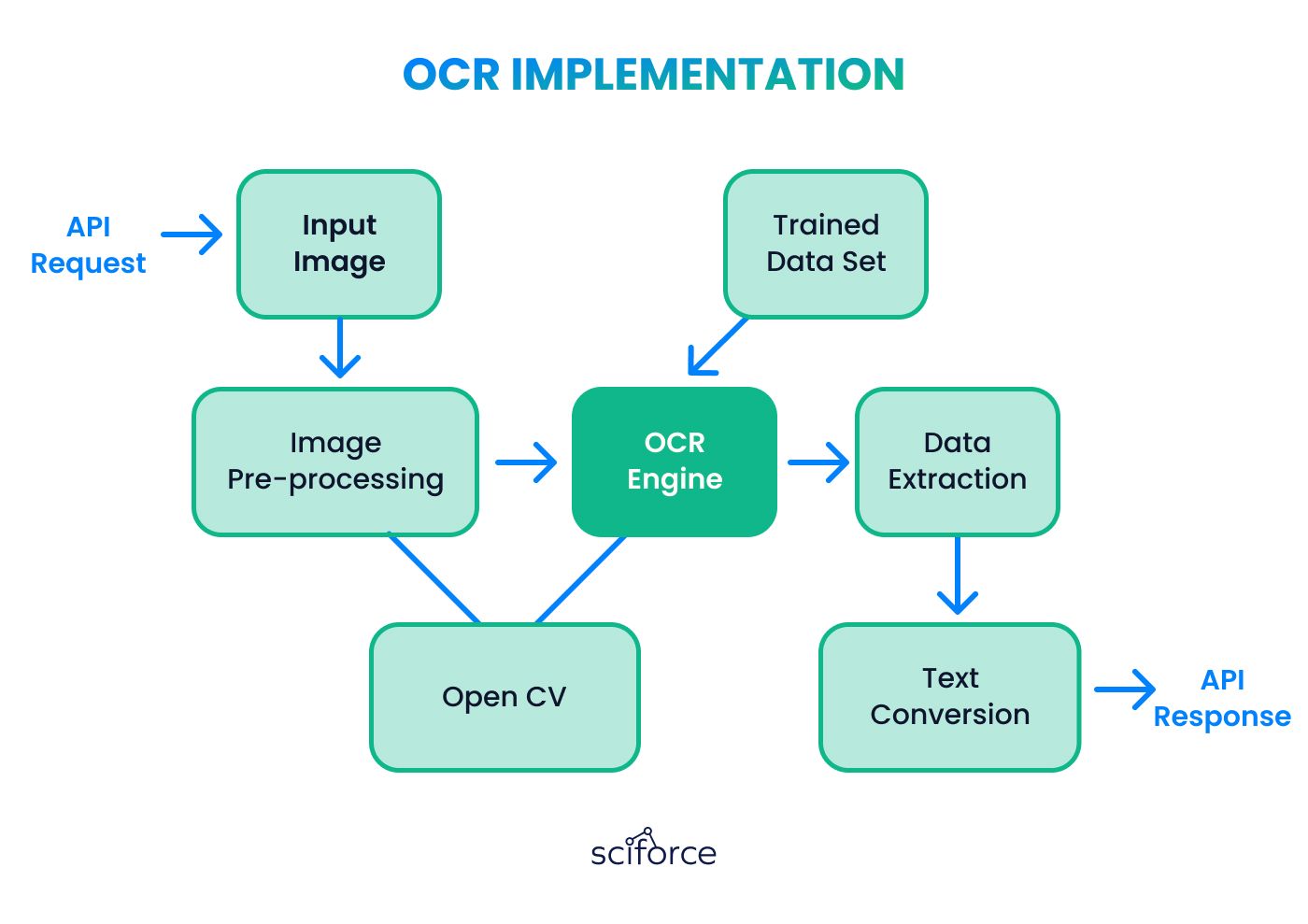
Text Extraction
Uses Optical Character Recognition (OCR) to extract text from the processed images within the detected boundaries, ensuring accurate text recognition.
Data Structuring
Organizes the extracted text into a structured format, categorizing elements such as order lists and VAT calculations.
Post-processing
Identifies and corrects errors in the extracted data. This includes editing the image if necessary and ensuring keywords correspond to the correct statements, handling the most frequent errors.
Feedback Loop
Implemented a feedback loop allowing users to report inaccuracies easily. This feedback was reviewed, added to the dataset, and used to retrain the model, continuously improving accuracy and handling variability.
Image Enhancement
Edited the source images to improve quality, including noise removal and upsampling using Generative Adversarial Networks (GANs). This step ensured that low-resolution images were enhanced to a higher resolution, making them suitable for further processing.
Classical Image Processing Techniques and Geometric Transformations
Applied geometric transformations to align and correct receipt images, making them look like scanned documents. Used model-based image enhancement (GANs/diffusion) only for edge cases to maintain cost-effectiveness.
Model Training
Collected a comprehensive dataset containing various receipt images with clearly labeled check boundaries. This dataset was used to train a YOLO model, designed to detect the edges and boundaries of receipts. The training process involved teaching the model to recognize different receipt formats and accurately identify their perimeters.
Detection
Deployed the trained YOLO model to automatically detect and delineate the boundaries of receipts in real-time. The model accurately localized the receipts within the images, drawing precise bounding boxes around them.
Text Extraction
We used Tesseract for Optical Character Recognition (OCR) to extract text from processed images within the accurately detected receipt boundaries. Tesseract was configured to recognize various fonts and languages commonly found on receipts, ensuring high accuracy in text extraction.
For more complex tasks requiring maximum accuracy, it’s possible to use high-end OCR models via APIs, such as Microsoft Vision 3.0.
Text Processing
Converted the extracted text from taxi receipts into organized, structured data formats. This included categorizing details such as ride dates, pickup and drop-off locations, fare amounts, tip amounts, total charges, and VAT calculations.
LLM Training
Trained a Large Language Model (LLM) named Gemma 2B to accurately extract and categorize data from taxi receipts into specific groups, such as ride details, fare breakdowns, and VAT information. Employed LoRA-based (Low-Rank Adaptation) training techniques to optimize the model by focusing on specific attention layers.
Dataset Preparation
Compiled a high-variance dataset consisting of taxi receipts from various services and regions. This dataset included a wide range of templates with variations in structures, ride details, date formats, currency symbols, and other receipt elements, to teach the model accurately deal with variability in real receipts.
Identified and corrected common errors in the extracted data from taxi receipts. This involved adjusting misrecognized text, such as correcting fare amounts, dates, and location names. Edited images to remove artifacts or distortions that could affect text accuracy.
- YOLO (You Only Look Once): Trained a model to accurately detect and delineate the boundaries of taxi receipts within images.
Efficiency & Cost-Effectiveness
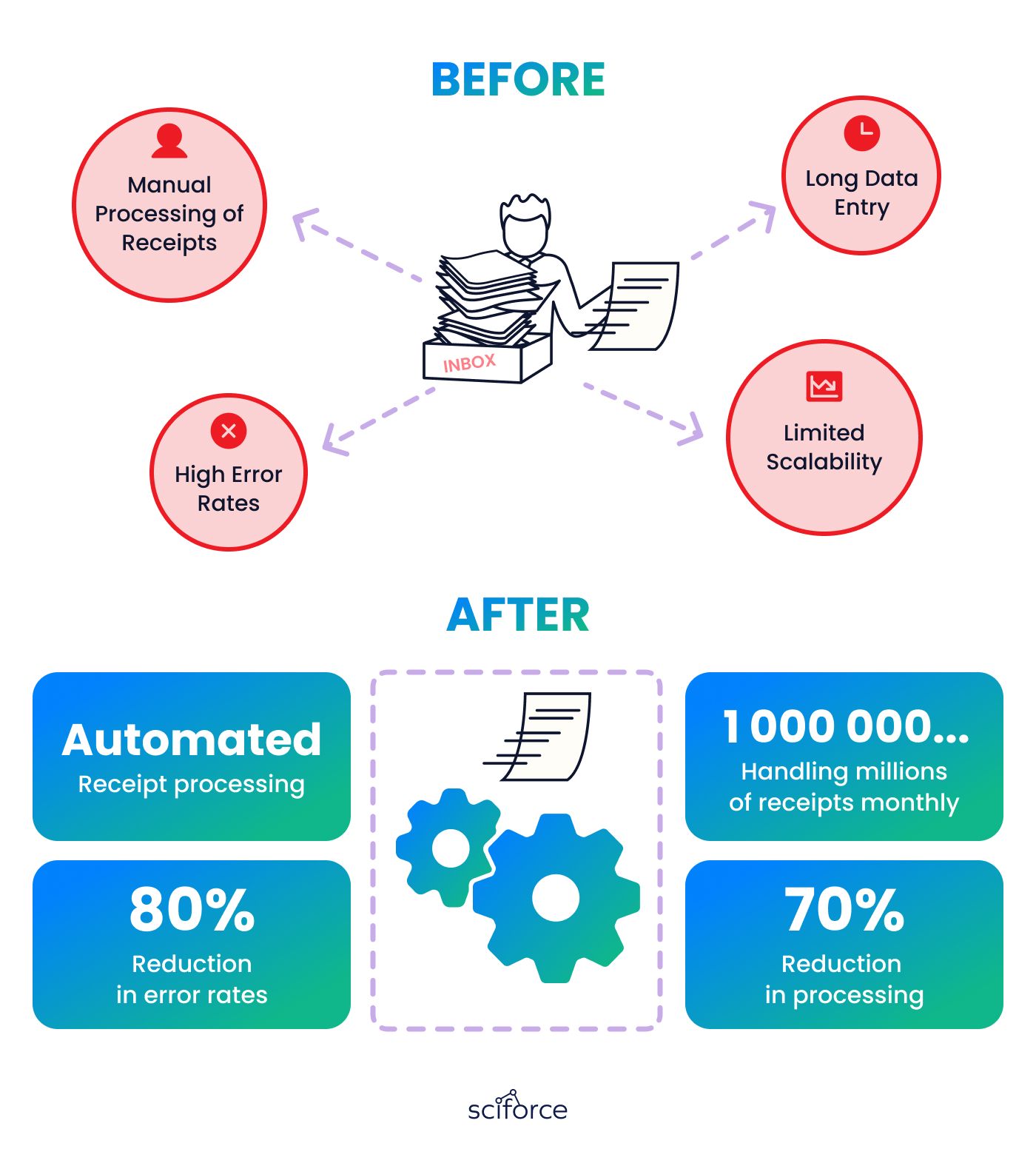
The solution removed the need for manual data entry, increasing the efficiency of receipt processing by 80% and cutting the costs by 50%.
Scalability
The solution enabled the client to scale their operations effectively, handling millions of receipts per month.
Accurate Data Extraction
The accuracy of data extraction improved by 80%, enhancing the reliability of financial records. This led to higher client satisfaction and trust, resulting in increased client retention and loyalty.
Faster Reimbursement
Quicker processing times led to faster reimbursements for taxi drivers and companies. This reduced the waiting period for payments, improved cash flow, and allowed for more efficient financial planning and operations.
We’ve upgraded the taxi receipt management system for a FinTech client. Our AI solution made processing 80% faster and more accurate, even with tough receipt formats and bad image quality
