
Our client is a law firm from Sweden dealing with a large number of complex agreements every day. Their main tasks involve reviewing detailed contracts related to partnership agreements, non-disclosure agreements, and service contracts, all requiring careful attention to maintain their high standards of service and client trust.
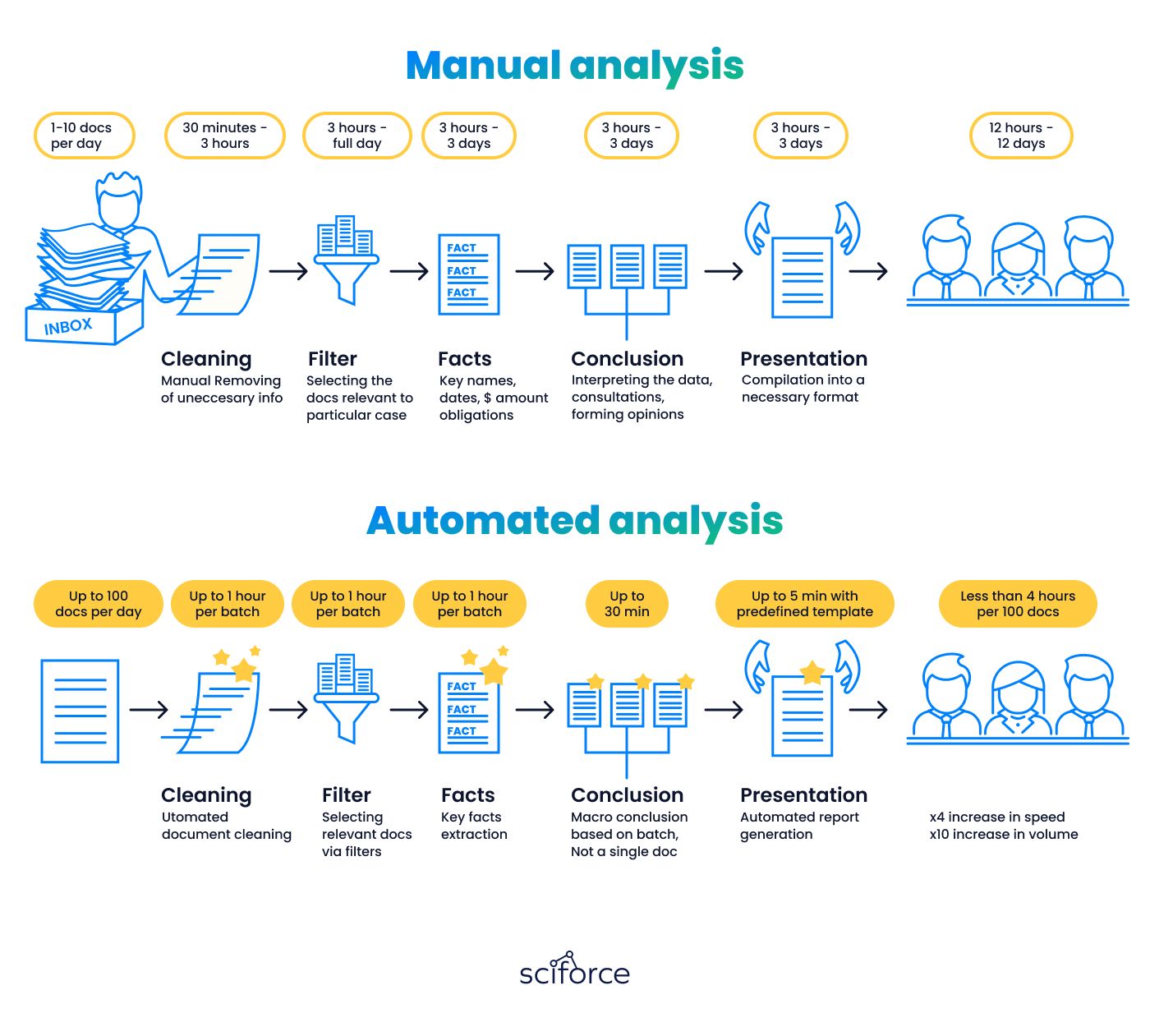
Overwhelming with documents of diverse format and content is a common challenge in the entire legal industry. Our client aimed to remove this bottleneck, reducing time spent on manual review, and improving data extraction accuracy. Another objective was to improve overall operational efficiency and data security in handling legal agreements.
Their document management process was entirely manual, involving multiple steps without effective data extraction or analytics tools. As a result, their system was imprecise and inefficient in both time and cost. Below is a depiction of the company's agreement analysis process:
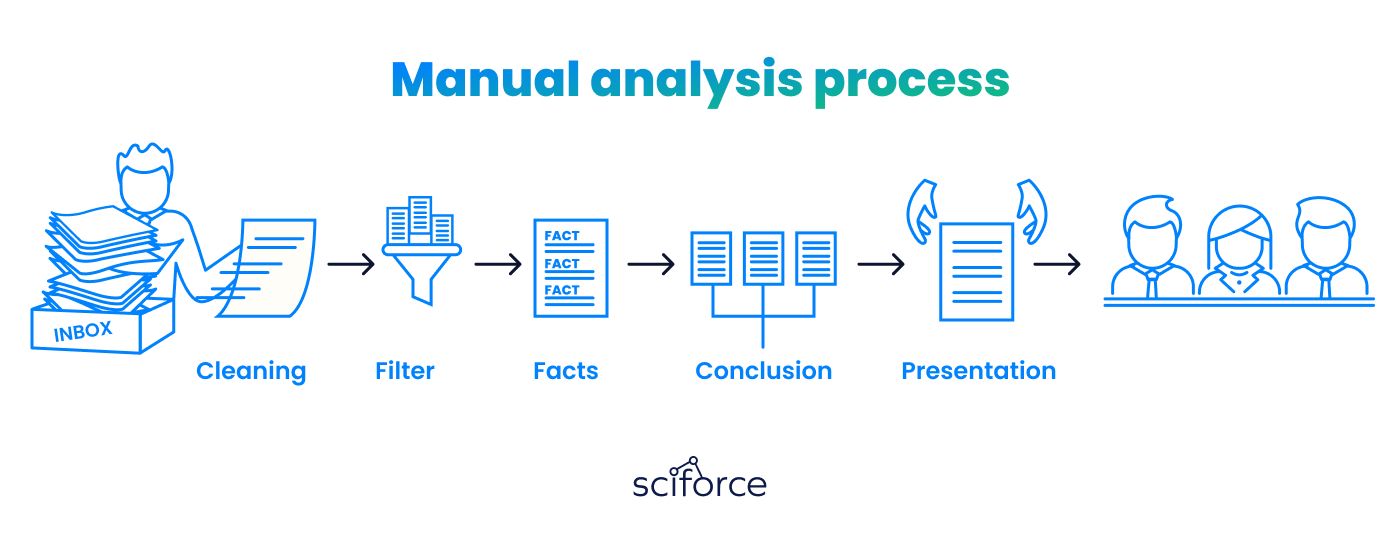
Human analysts managed most stages smoothly, but the system failed to deliver results at the fact analysis stage due to several issues:
Our discovery phase showed that identifying clauses and facts in agreements was a major challenge with the current document management system. Clearly, AI tools were a perfect solution for the company's issues with document classification and processing. It was intended to use NLP to detect named entities, analyze semantics, and understand text relationships. Here is why it didn’t work:
We ended up training an ML model to recognize and classify various facts and clauses within the documents. Potentially, it would need a great number of documents in a training dataset, however the combination of the Gaussian Model and TF-IDF & PCA showed decent accuracy on a small dataset of 50 docs. It was also possible to add a new solution, a rule type, a new clause subtype, or even a new language, without making code changes.
Roadmap Optimization
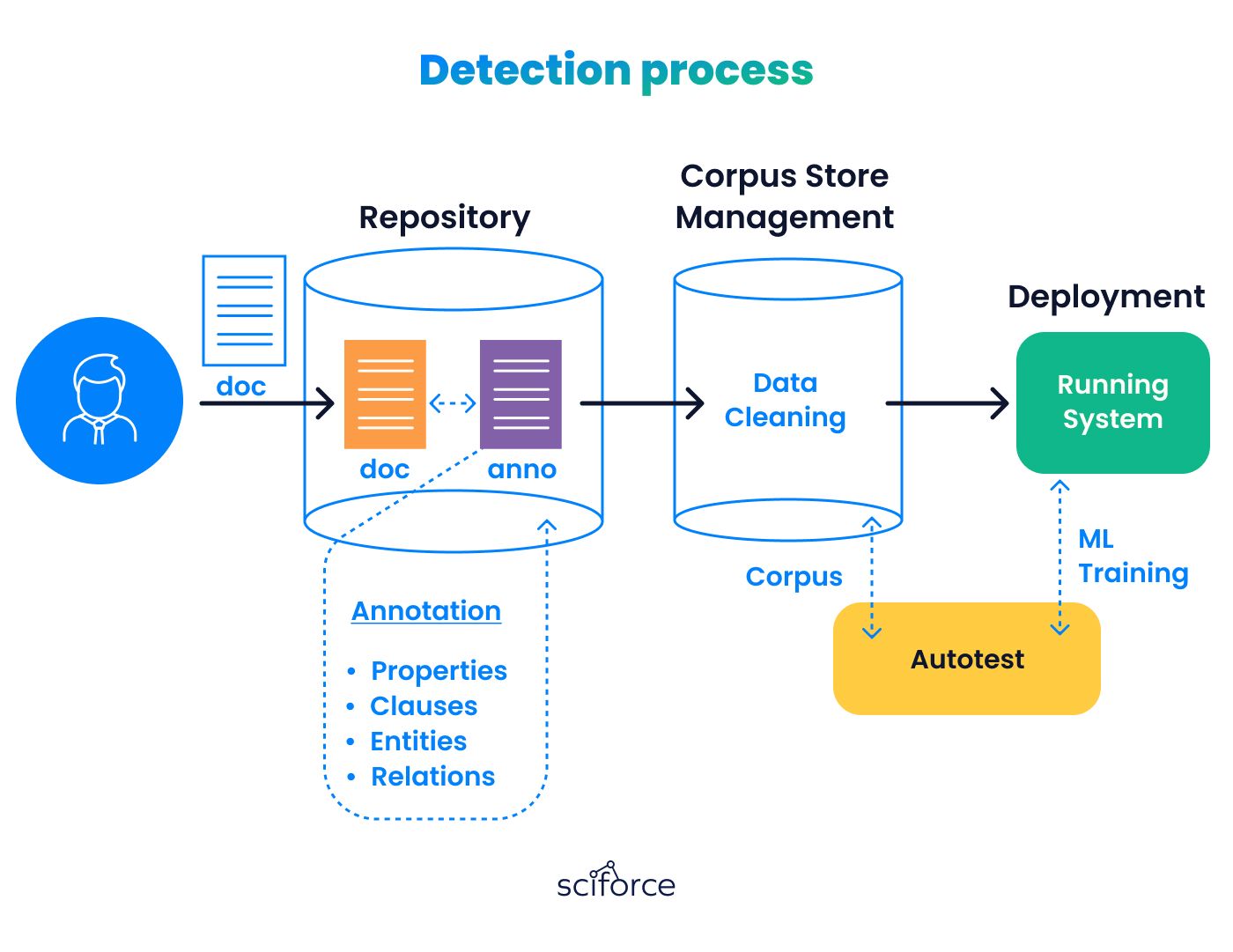
Document Receipt and Storage:
Initially, any received external document is stored in a document repository.
- Document Annotation Process:
Data Preparation for ML Training:
Finally, the prepared data is deployed to the system where the actual ML model training takes place.
The initial step in analyzing documents is to figure out the relevant law and the language used. While this might seem straightforward to a person, machines need the help of machine learning (ML) algorithms to accurately identify the language.
We decided to use an ML model to find key sentences, then look for topological entities or language names within them. To prevent the model from overfitting to a particular term or location, we automatically switched between a random language or country during the training. It forced the model to recognize the important legal and language details based on the context of the words, rather than just spotting the names of languages or countries.
The next step in our process is to sort the document and its different clauses. Although agreements usually have a standard format, the real arrangement, titles, and details of these sections often change a lot. This makes it hard to quickly sort the texts of agreements. To solve this, we created a strong system for sorting based on the Gaussian Model that can handle this variety of clauses.
It uses math to figure out which category a section likely belongs to, based on its characteristics. It makes our system better at placing sections into the right categories, even when they don't follow the usual patterns.
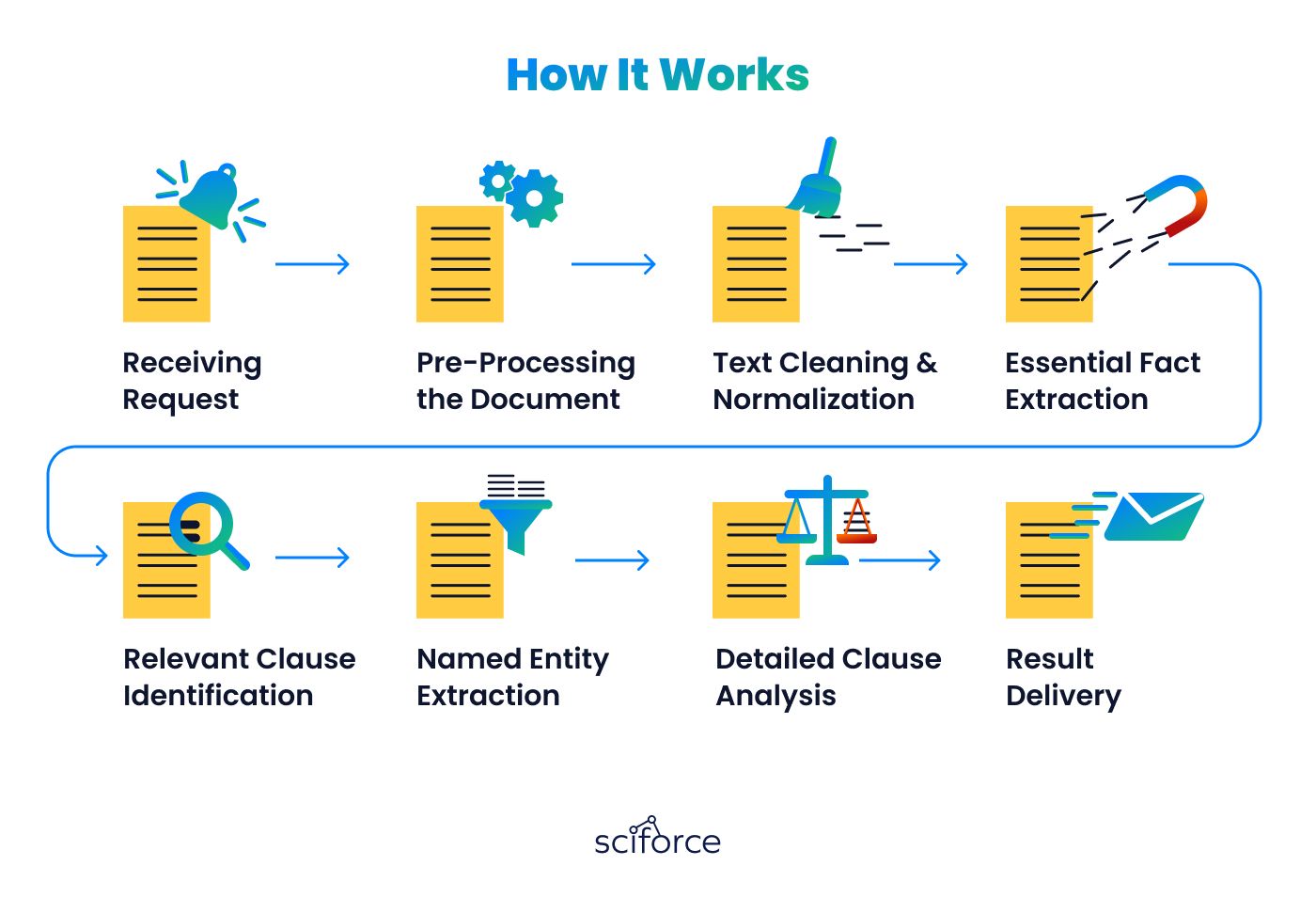
Our agreement analysis process automates extracting crucial information from legal texts, aimed at reducing manual work for legal professionals. It is based on two main stages:
This method ensures efficient and accurate document analysis, freeing up legal experts to focus on more complex tasks. Initially trained on a dataset of 50 documents, the system has a potential to process large amounts of documents and learn to understand new types of agreements.
We tested various machine learning models, including classification tree ensembles for accurate classification and information extraction from legal documents. We also used Gaussian Processes to predict the characteristics of different entity types in legal texts.
Feature Selection and Optimization
Arbitration and Court Detection
Our system identifies arbitration and court references in contracts by analyzing sentences, based on the idea that each sentence usually discusses one arbitration-court pairing. We assumed that a single sentence might mention more than one arbitration or court case, so we've developed machine learning models with multiple outputs, using a mix of classification trees. Specifically, we employ a combination of classification trees, with 5 outputs corresponding to 5 court types present in the markup. For every court type the system finds, it assigns a number that matches it with a particular type of arbitration, helping us accurately spot and categorize these legal references and how they're connected.
Dispute Subtype Detection
Unlike other analyses, identifying dispute subtypes required examining entire dispute clauses, not just isolated sentences or paragraphs. This broader context allows us to better apply TF-IDF or Word2Vec features, further informed by the outcomes of a solution-rule classification to accurately determine the type of dispute being discussed.
We make it easy to handle, analyze, and store legal documents. Here is the list of improvements our system brought:
Smart Document Sorting:
Automatically identifies texts and sorts documents into specific categories based on set patterns. This maintains accurate document flow without needing much human intervention and allows lawyers to focus on high-value client work, rather than tedious paper one.
Turning Data into Insights:
It pulls valuable information from unstructured text, such as expiration dates or liability terms, allowing for better management of contract obligation and avoiding potential legal pitfalls.
Handling Large Data Volumes:
The system is capable of processing large doc volumes at a time, ensuring accuracy and reliability of operations. This allows the firm to handle increased workloads without errors or delays in client projects.
Forecasting Document Flow:
With understanding of upcoming needs, the law firms can ensure better compliance with deadlines and prepare in advance for audits, reviews, and reporting periods.
Robust Document Security:
With manual processing, there is always a risk that some important paper will get lost or go to the wrong folder. Autonation minimizes it, ensuring strict order, protection from unauthorized access, and regulatory compliance.
Flexible Model Adjustment:
It is easy to adjust the model to everyday needs by adding new solutions and rules, without the need to make code changes. This allows the firm to be flexible and to adjust their document flow based on workload, deadlines, and reporting periods.
Our AI-powered system has revolutionized contract analysis for our clients, making the review process faster, enhancing clause detection accuracy, and streamlining document management. Notable improvements include:
- Enhanced Clause Detection:
Our advancements have led to a remarkable over 95% accuracy rate in identifying various types of clauses and their intricate details, such as confidentiality terms, cost sharing arrangements, and complexities involved in multiparty and multi-contract scenarios.
- Precise Identification of Text Elements:
The system's refined capabilities allow for the precise identification of smaller text fragments, including legal terminologies, rules, and geographic details, and adeptly establishes the relationships between these elements, such as associating a legal rule with its corresponding solution.
- Automated Large-Scale Data Analysis:
The introduction of automated processing for vast data sets via HTTP REST/JSON API and a message bus, followed by orderly storage in Docker Images/Containers, has cut down document processing time by half, allowing for rapid scaling of document analysis.
Optimize your legal operations with SciForce's advanced document automation technology. We can develop an automated document processing system tailored to your specific needs, whether you are a law firm or just have lots of agreements with clients or contractors.
Tailored to your specific workflow, our system will free your employees from tedious paperwork and reallocate their time for strategic, high-value tasks.
Ready to transform your contract management and gain a competitive edge? Contact us to discover how SciForce can address your paperwork challenges.


