In his speech at Web Summit 2018, Yves Bernaert, the Senior Managing Director at Accenture, declared the quest for data veracity that will become increasingly important for getting sense of Big Data. In short, Data Science is about to turn from data quantity to data quality.
It is true, that data veracity, though always present in Data Science, was outshined by other three big V’s: Volume, Velocity and Variety.
For Data Analysis we need enormous volumes of data. Luckily, today data is provided not only by human experts but by machines, networks, readings from connected devices and so on. It can be said that in most cases, we have enough data around us. What we need now is to select what might be of use.
In the field of Big Data, velocity means the pace and regularity at which data flows in from various sources. It is important, that the flow of data is massive and continuous, and the data could be obtained in real time or with just a few seconds delay. This real-time data can help researchers make more accurate decisions and provide a fuller picture.
For the data to be representative, it should come from various sources and in many types. At present, there are many kinds of structured and unstructured data in diverse formats: spreadsheets, databases, sensor readings, texts, photos, audios, videos, multimedia files, etc. Organization of this huge pool of heterogeneous data, its storage and analyzing have become a big challenge for data scientists.
In most general terms, data veracity is the degree of accuracy or truthfulness of a data set. In the context of big data, it’s not just the quality of the data that is important, but how trustworthy the source, the type, and processing of the data are.
The need for more accurate and reliable data was always declared, but often overlooked for the sake of larger and cheaper datasets.
It is true that the previous data warehouse / business intelligence (DW/BI) architecture tended to spend unreasonably large amounts of time and effort on data preparation trying to reach high levels of precision. Now, with incorporation of unstructured data, which is uncertain and imprecise by definition, as well as with the increased variety and velocity, businesses cannot allocate enough resources to clean up data properly.
As a result, data analysis is to be performed on both structured and unstructured data that is uncertain and imprecise. The level of uncertainty and imprecision varies on a case by case basis, so it might be prudent to assign a Data Veracity score and ranking for specific data sets.
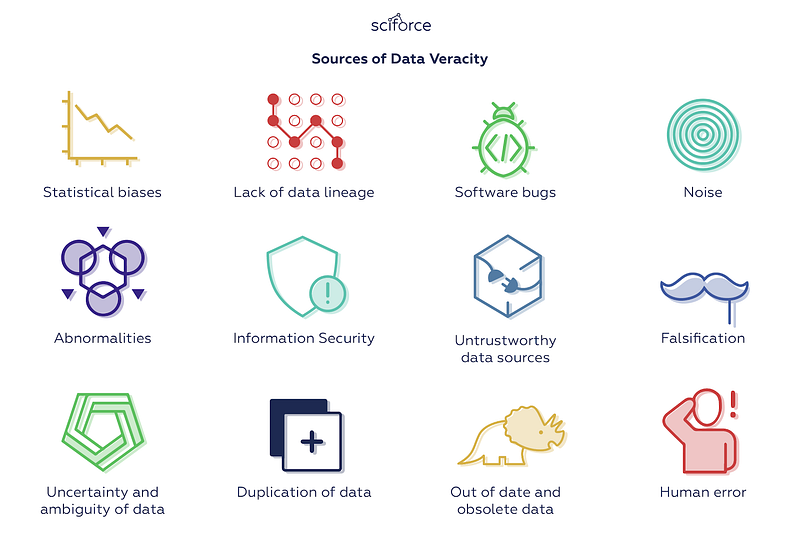
Sources of Data Veracity
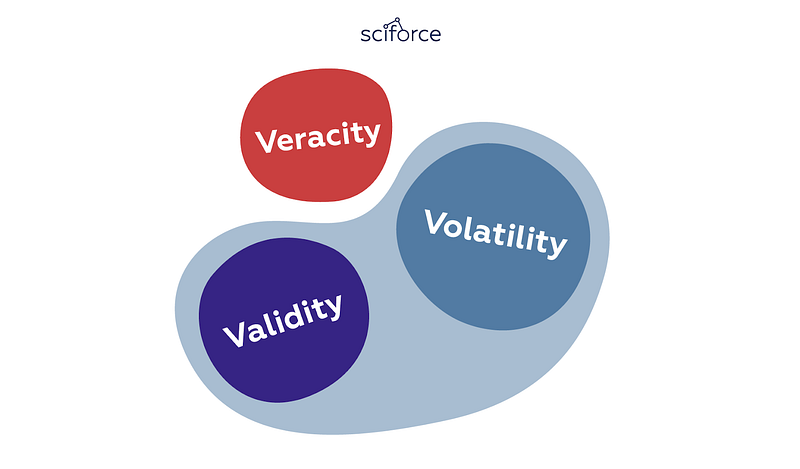
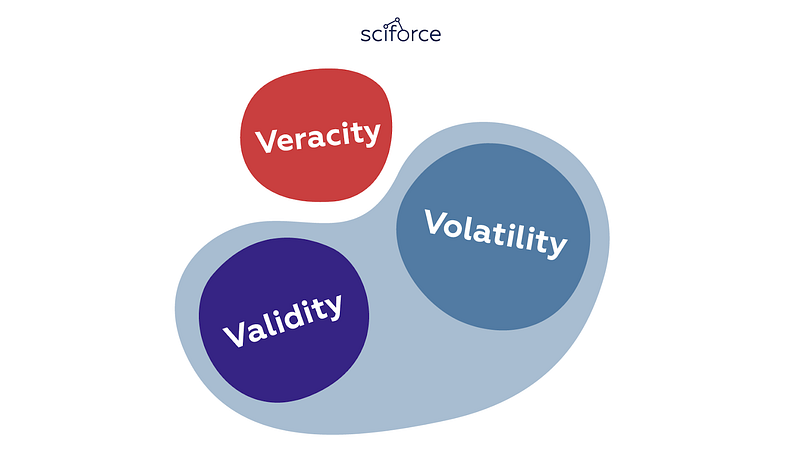
Data veracity has given rise to two other big V’s of Big Data: validity and volatility:
Springing from the idea of data accuracy and truthfulness, but looking at them from a somewhat different angle, data validity means that the data is correct and accurate for the intended use, since valid data is key to making the right decisions.
Volatility of data, in its turn, refers to the rate of change and lifetime of the data. To determine whether the data is still relevant, we need to understand how long a certain type of data is valid. Such data like social media where sentiments change quickly is highly volatile. Less volatile data like weather trends, is easier to predict and track. Yet, unfortunately, sometimes volatility isn’t within our control.
Big data is extremely complex and it is still to be discovered how to unleash its potential. Many think that in machine learning the more data we have the better, but, in reality, we still need statistical methods to ensure data quality and practical application. It is impossible to use raw big data without validating or explaining it. At the same time, big data does not have a strong foundation with statistics. That is why researchers and analysts try to understand data management platforms to pioneer methods that integrate, aggregate, and interpret data with high precision. Some of these methods include indexing and cleaning the data that are used on primary data to give more context and maintain the veracity of insights.
In this case, only trustworthy data can add value to your analysis and machine learning algorithms and the emphasis on its veracity will only grow with data sets growing in volume and variety.