Each nation has its ancient monument or a pagan holiday — the relic of the days when our ancestors tried to persuade their gods to give them more rain, no rain, better harvest, fewer wars and many other things considered essential for survival. However, neither Stonehenge nor jumping over fire could predict the gods’ reaction. It was a totally reactive world with no forecast. However, as time passed, people started to look into the future more inquisitively trying to understand what would be waiting for them. The science of prediction has emerged.
In this article, we’ll see how prediction evolved over time shaping our technologies, expectations and the worldview.
Naïve forecasting is an estimating technique in which the last period’s values are used as this period’s forecast, without adjusting them or attempting to establish causal factors. In other words, a naive forecast is just the most recently observed value. It is calculated by the formula
Ft+k=yt
where at the time t, the k-step-ahead naive forecast (Ft+k) equals the observed value at time t (yt).
In Ancient times, before such formulas, communities typically relied on observed patterns and recognized sequences of events for weather forecasting. The remnants of these techniques we can see in our everyday lives: we can foresee the next Monday routine based on the previous Monday, or expect spring to come in March (even though such expectations rely more on our imagination than the recorded seasonal changes).
In industry and commerce, it is used mainly for comparison with the forecasts generated by the better (sophisticated) techniques. However, sometimes this is the best that can be done for many time series including most stock price data. It also helps to baseline the forecast by tracking naïve forecast over time and estimating the forecast value added to the planning process. It reveals how difficult products are to forecast, whether it is worthwhile to spend time and effort on forecasting with more sophisticated methods and how much that method adds to the forecast.
Even if it is not the most accurate forecasting method, it provides a useful benchmark for other approaches.
Statistical forecasting is a method based on a systematic statistical examination of data representing past observed behavior of the system to be forecast, including observations of useful predictors outside the system. In simple terms, it uses statistics based on historical data to project what could happen out in the future.
As the late 19th and early 20th centuries were stricken by a series of crises that lead to severe panics — in 1873, 1893, 1907, and 1920 — and also substantial demographic change, as countries moved from being predominantly agricultural to being industrial and urban, people were struggling to find stability in the volatile world. Statistics-based forecasting invented at the beginning of the 20th century showed that economic activity was not random, but followed discernable patterns that could be predicted.
The two major statistical forecasting approaches are time series forecasting and model-based forecasting.
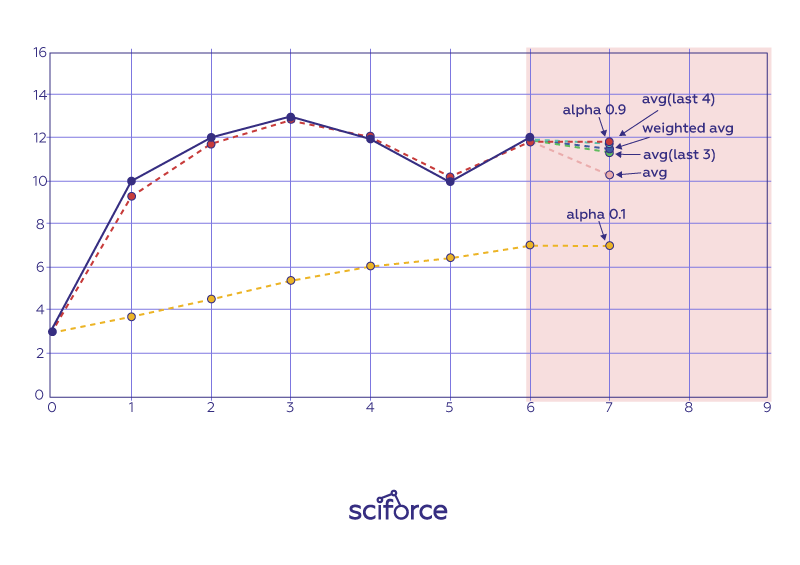
Time Series forecasting is a short-term purely statistical forecasting method that predicts short-term changes based on historical data. It is working on time (years, days, hours, and minutes) based data, to find hidden insights. The simplest technique of Time Series Forecasting is a simple moving average (SMA). It is calculated by adding up the last ’n’ period’s values and then dividing that number by ’n’. So the moving average value is then used as the forecast for next period.
Model-Based Forecasting is more strategic and long-term, and it accounts for changes in the business environment and events with little data. It requires management. Model-based forecasting techniques are similar to conventional predictive models which have independent and dependent variables, but the independent variable is now time. The simplest of such methods is the linear regression. Given a training set, we estimate the values of regression coefficients to forecast future values of the target variable.
With time the basic statistical methods of forecasting have seen significant improvements in approaches, forming the spectra of data-driven forecasting methods and modeling techniques.
Data-driven forecasting refers to a number of time-series forecasting methods where there is no difference between a predictor and a target. The most commonly employed data-driven time series forecasting methods are Exponential Smoothing and ARIMA Holt-Winters methods.
Exponential smoothing was first suggested in the statistical literature without citation to previous work by Robert Goodell Brown in 1956. Exponential smoothing is a way of “smoothing” out data by removing much of the “noise” from the data by giving a better forecast. It assigns exponentially decreasing weights as the observation gets older:
y^x=α⋅yx+(1−α)⋅y^x−1
where we’ve got a weighted moving average with two weights: α and 1−α.
This simplest form of exponential smoothing can be used for short-term forecast with a time series that can be described using an additive model with constant level and no seasonality.
Charles C. Holt proposed a variation of exponential smoothing in 1957 for a time series that can be described using an additive model with increasing or decreasing trend and no seasonality. For a time series that can be described using an additive model with increasing or decreasing trend and seasonality, Holt-Winters exponential smoothing, or Triple Exponential Smoothing, would be more accurate. It is an improvement of Holt’s algorithms that Peter R. Winters offered in 1960.
The idea behind this algorithm is to apply exponential smoothing to the seasonal components in addition to level and trend. The smoothing is applied across seasons, e.g. the seasonal component of the 3rd point into the season would be exponentially smoothed with the one from the 3rd point of last season, 3rd point two seasons ago, etc.
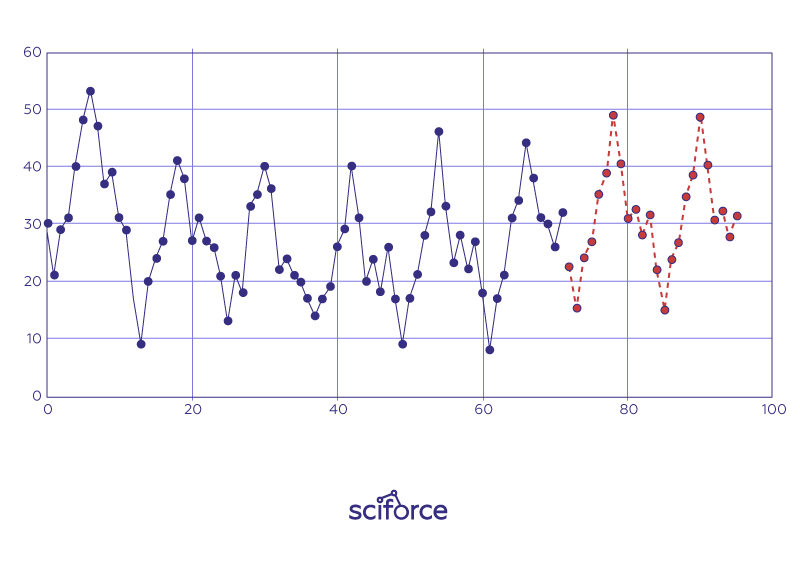
Here we can see evident seasonal trends that are supposed to continue in the proposed forecast.
ARIMA is a statistical technique that uses time series data to predict future. It is are similar to exponential smoothing in that it is adaptive, can model trends and seasonal patterns, and can be automated. However, ARIMA models are based on autocorrelations (patterns in time) rather than a structural view of level, trend and seasonality. All in all, ARIMA models take trends, seasonality, cycles, errors and non-stationary aspects of a data set into account when making forecasts. ARIMA checks stationarity in the data, and whether the data shows a constant variance in its fluctuations over time.
The idea behind ARIMA is that the final residual should look like white noise; otherwise there is information available in the data to extract.
ARIMA models tend to perform better than exponential smoothing models for longer, more stable data sets and not as well for noisier, more volatile data.
While many of time-series models can be built in spreadsheets, the fact that they are based on historical data makes them easily automated. Therefore, software packages can produce large amounts of these models automatically across large data sets. In particular, data can vary widely, and the implementation of these models varies as well, so automated statistical software can assist in determining the best fit on a case by case basis.
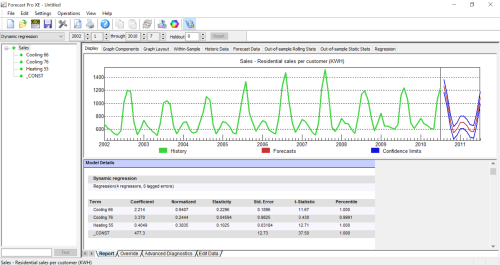
A step forward compared to pure time series models, dynamic regression models allow incorporating causal factors such as prices, promotions and economic indicators into forecasts. The models combine standard OLS (“Ordinary Least Squares”) regression (as offered in Excel) with the ability to use dynamic terms to capture trend, seasonality and time-phased relationships between variables.
A dynamic regression model lends insight into relationships between variables and allows for “what if” scenarios. For example, if we study the relationship between sales and price, the model allows us to create forecasts under varying price scenarios, such as “What if we raise the price?” “What if we lower it?” Generating these alternative forecasts can help you to determine an effective pricing strategy.
A well-specified dynamic regression model captures the relationship between the dependent variable (the one you wish to forecast) and one or more (in cases of linear or multiple regressions, respectively) independent variables. To generate a forecast, you must supply forecasts for your independent variables. However, some independent variables are not under your control — think of weather, interest rates, price of materials, competitive offerings, etc. — you need to keep in mind that poor forecasts for the independent variables will lead to poor forecasts for the dependent variable.
Forecasting demand for electricity using data on the weather (e.g. when people are likely to run their heat or AC).
In contrast to time series forecasting, regression models require knowledge of the technique and experience in data science. Building a dynamic regression model is generally an iterative procedure, whereby you begin with an initial model and experiment with adding or removing independent variables and dynamic terms until you arrive upon an acceptable model. Everyone who ever had a look at data or computer science knows that linear regression is in fact the basic prediction model in machine learning, which brings us to the final destination of our journey — Artificial Intelligence.
Artificial intelligence and machine learning are considered the tools that can revolutionize forecasting. An AI that can take into account all possible factors that might influence the forecast gives business strategists and planners breakthrough capabilities to extract knowledge from massive datasets assembled from any number of internal and external sources. The application of machine learning algorithms in the so called predictive modeling unearths insights and identifies trends missed by traditional human-configured forecasts. Besides, AI can simultaneously test and learn, constantly refining hundreds of advanced models. The optimal model can then be applied at a highly granular SKU-location level to generate a forecast that improves accuracy.
Among multiple models and techniques for prediction in ML and AI inventory, we have chosen one that is closest to our notion of a truly independent artificial intelligence. Artificial neural network (ANN) is a machine learning approach that models the human brain and consists of a number of artificial neurons. Neural networks can derive meaning from complicated or imprecise data and are used to detect the patterns and trends in the data, which are not easily detectable either by humans or by machines.
We can make use of NNs in any type of industry, as they are very flexible and also don’t require any algorithms. They are regularly used to model parts of living organisms and to investigate the internal mechanisms of the brain.
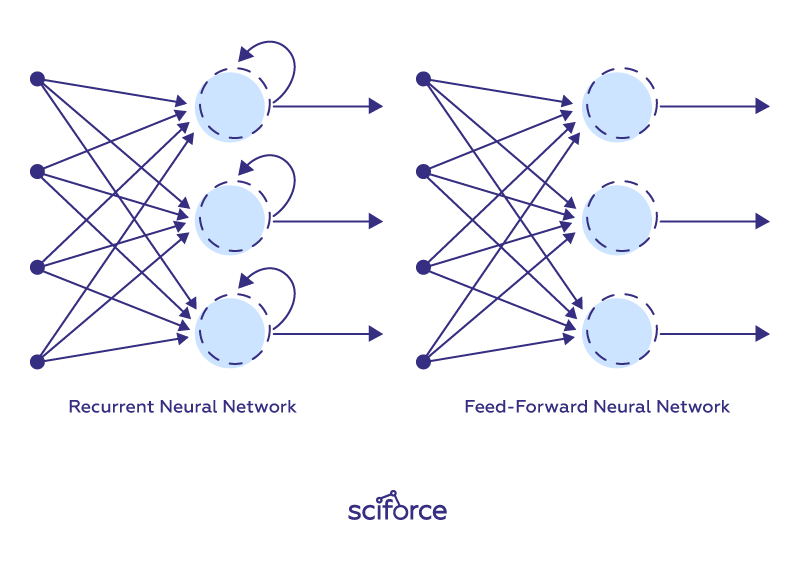
The simplest neural network is a fully Connected Model which consists of a series of fully connected layers. In a fully connected layer each neuron is connected to every neuron in the previous layer, and each connection has its own weight. Such model resembles a simple regression model that takes one input and will spit out one output. It basically takes the price from the previous day and forecasts the price of the next day. Such models repeat the previous values with a slight shift. However, fully connected models are not able to predict the future from the single previous value.
With the latest emergence of Deep Learning techniques, neural networks have seen significant improvements in terms of accuracy and ability to tackle the most sophisticated and complex tasks. Recently introduced recurrent neural networks deal with sequence problems. They can retain a state from one iteration to the next by using their own output as input for the next step. In programming terms, this is like running a fixed program with certain inputs and some internal variables. Such models can learn to reproduce the yearly shape of the data and don’t have the lag associated with a simple fully connected feed-forward neural network.
With the development of Artificial Intelligence, forecasting as we knew it has transformed itself into a new phenomenon. Traditional forecasting is a technique that takes data and predicts the future value for the data looking at its unique trends. Artificial Intelligence and Big Data introduced predictive analysis that factors in a variety of inputs and predicts the future behavior — not just a number. In forecasting, there is no separate input or output variable but in the predictive analysis you can use several input variables to arrive at an output variable.
While forecasting is insightful and certainly helpful, predictive analytics can provide you with some pretty helpful people analytics insights. People analytics leaders have definitely caught on.