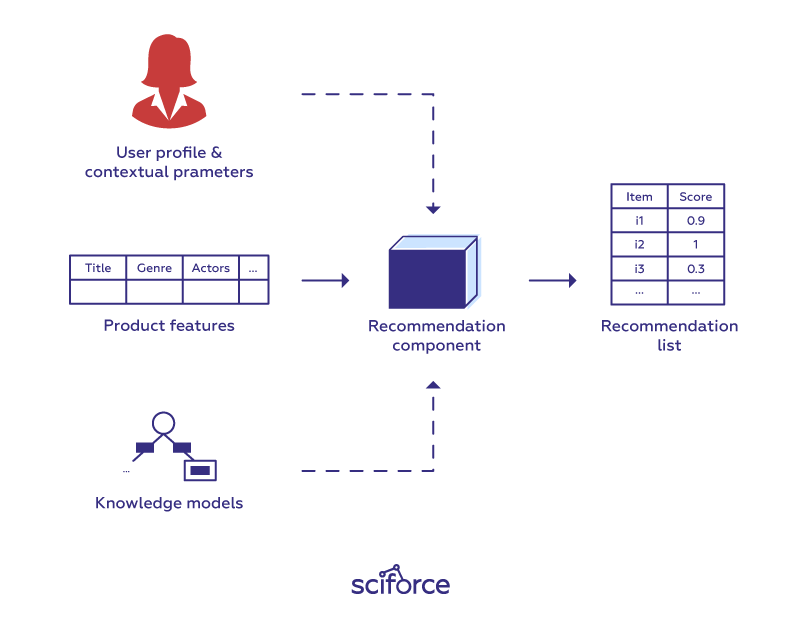
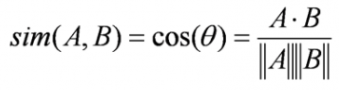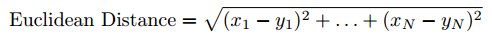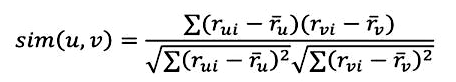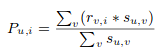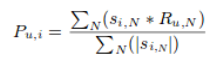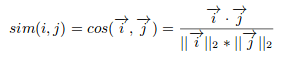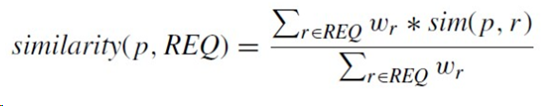If we think of the most successful and widespread applications of machine learning in business, one of the examples would be recommender systems. Each time you visit Amazon or Netflix, you see recommended items or movies that you might like — the product of recommender systems incorporated by these companies. Though a recommender system is a rather simple algorithm that discovers patterns in a dataset, rates items and shows the user the items that they might rate highly, they have the power to boost sales of many e-commerce and retail companies.
In simple words, these systems predict users’ interests and recommend relevant items.
Recommender systems rely on a combination of data stemming from explicit and implicit information on users and items, including:
Characteristic information, including information about items, such as categories, keywords, etc., and users with their preferences and profiles, and
User-item interactions — the information about ratings, number of purchases, likes, and so on.
Based on this, recommender systems fall into two categories: content-based systems that use characteristic information, and collaborative filtering systems based on user-item interactions. Besides, there is a complementary method called knowledge-based system that relies on explicit knowledge about the item, the user and recommendation criteria, as well as the class of hybrid systems that combine different types of information.
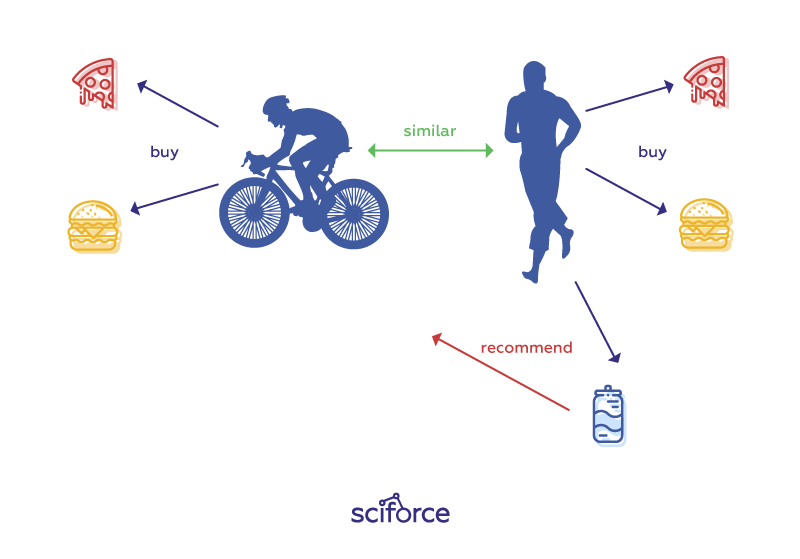
Such systems make recommendations based on the user’s item and profile features. The idea underlying them is that if a user was interested in an item in the past, they will be interested in similar items later. User profiles are constructed using historical interactions or by explicitly asking users about interests. Of course, pure content-based systems tend to make too obvious recommendations — because of excessive specialization — and to offer too many similar items in a row. Well suited for movies, if you want to want all films starring the same actor, these systems fall short in e-commerce, spamming you with hundreds of watches or shoes.
Cosine similarity: the algorithm finds the cosine of the angle between the profile vector and item vector:
Based on the cosine value, which ranges between -1 to 1, items are arranged in descending order and one of the two below approaches is used for recommendations:
Euclidean Distance: since similar items lie in close proximity to each other if plotted in n-dimensional space, we can calculate the distance between items and use it to recommend items to the user:
However, Euclidean Distance performance falls in large-dimensional spaces, which limits the scope of its application.
Pearson’s Correlation: the algorithm shows how much two items are correlated, or similar:
A major drawback of this algorithm is that it is limited to recommending items that are of the same type.
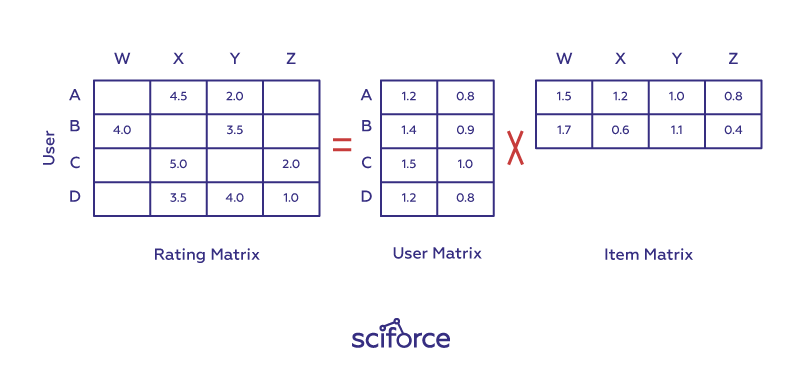
Unlike content-based systems, they utilize user interactions and the preference of other users to filter for items of interest. The baseline approach to collaborative filtering is matrix factorization. The goal is to complete the unknowns in the matrix of user-items interactions (let’s call it R_R_). Suppose we have two matrices U_U_ and I_I_, such that U \times I_U_×_I_ is equal to R_R_ in the known entries. Using the U \times I_U_×_I_ product we will also have values for the unknown entries of R_R_, which can then be used to generate the recommendations.
A smart way to find matrices U_U_ and I_I_ is by using a neural network. An interesting way of looking at this method is to think of it as a generalization of classification and regression. Though more intricate and smarter, they should have enough information to work, meaning cold start for new e-commerce websites and new users.
There are two types of collaborative models: memory-based and model-based:
Memory-based methods offer two approaches: to identify clusters of users and utilize the interactions of one specific user to predict the interactions of the cluster. The second approach identifies clusters of items that have been rated by a certain user and utilizes them to predict the interaction of the user with a similar item. Memory-based techniques are simple to implement and transparent, but they encounter major problems with large sparse matrices, since the number of user-item interactions can be too low for generating high-quality clusters.
In the algorithms that measure the similarity between users, the prediction of an item for a user u is calculated by computing the weighted sum of the user ratings given by other users to an item i. The prediction Pu,i is given by:
where
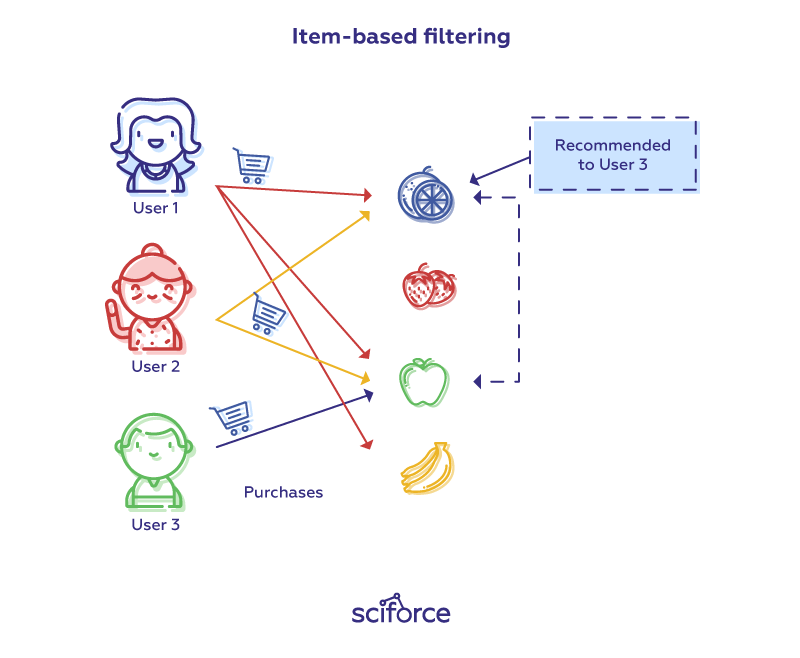
The algorithm finds the similarity between each item pair and, based on that, recommends similar items liked by users in the past. This algorithm works similar to user-user collaborative filtering with just a little change — instead of taking the weighted sum of ratings of “user-neighbors”, we take the weighted sum of ratings of “item-neighbors”. The prediction is given by:
Now we will find the similarity between items.
This way we can e.g. weigh users’ ratings of movies to find similar ones and make predictions to recommend similar movies to users.
Model-based methods are based on machine learning and data mining techniques to predict users’ ratings of unrated items. These methods are able to recommend a larger number of items to a larger number of users, compared to other methods like memory-based. Examples of such model-based methods include decision trees, rule-based models, Bayesian methods and latent factor models.
Knowledge-based recommender systems use explicit information about the item assortment and the client’s preference. Based on this knowledge, the system generates corresponding recommendations. If no item satisfies all the requirements, products satisfying a maximal set of constraints are ranked and displayed. Unlike other approaches, it does not depend on large bodies of statistical data about items or user ratings, which makes them especially useful for rarely sold items, such as houses, or when the user wants to specify requirements manually. Such an approach allows avoiding a ramp-up or cold start problem since recommendations do not depend on a base of user ratings. Knowledge-based recommender systems have a conversational style offering a dialog that effectively walks the user down a discrimination tree of product features.
Knowledge-based systems work on two approaches: constraint-based, relying on an explicitly defined set of recommendation rules, and case-based, taking intelligence from different types of similarity measures and retrieving items similar to the specified requirements.
Constraint-based recommender systems try to mediate between the weighted hard and soft user requirements (constraints) and item features. The system asks the user which requirements should be relaxed/modified so that some items exist that do not violate any constraint and finds a subset of items that satisfy the maximum set of weighted constraints. The items are afterwards ranked according to the weights of the constraints they satisfy and are shown to the user with an explanation of their placement in the ranking.
The case-based approach relies on the similarity distance,
where sim (p, r) expresses for each item attribute value p its distance to the customer requirement r ∈ REQʷᵣ is the importance weight for requirement r.
However, in real life, some users may want to maximize certain requirements, minimize others, or simply not be sure what they want, submitting queries that might look like “similar to Item A, but better”. In contrast to content-based systems, the conversational approach of knowledge-based recommenders allows for such scenarios by eliciting users’ feedback, called critiques.
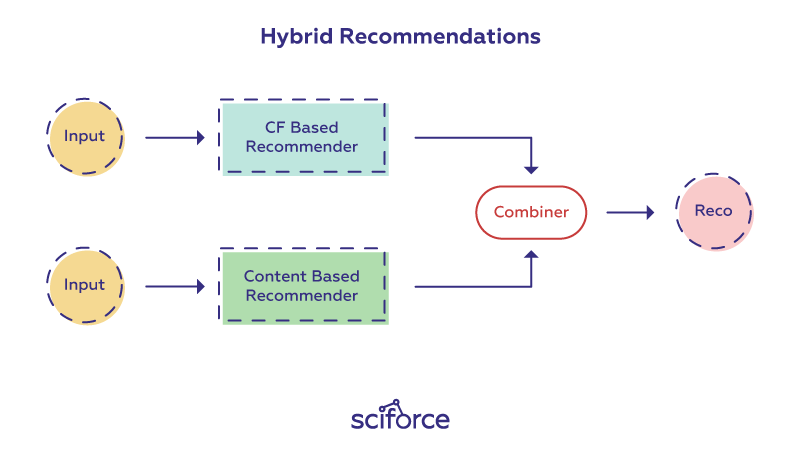
Recent research shows that to improve the effectiveness of recommender systems, it is worth combining collaborative and content-based recommendation. Hybrid approaches can be implemented by making content-based and collaborative-based predictions separately and then combining them by adding content-based capabilities to a collaborative-based approach and vice versa; or by unifying the approaches into one model. Netflix, for instance, makes recommendations by comparing the watching and searching habits of similar users (i.e., collaborative filtering) as well as by offering movies that share characteristics with films that a user has rated highly (content-based filtering).
Since a product recommendation engine mainly runs on data, data mining and storage are of primary concern.
The data can be collected explicitly and implicitly. Explicit data is information that is provided intentionally, i.e. input from the users such as movie ratings. Implicit data is information that is not provided intentionally but gathered from available data streams like search history, clicks, order history, etc. Data scraping is one of the most useful techniques to mine these types of data from the website.
The type of data plays an important role in deciding the type of storage that has to be used. This type of storage could include a standard SQL database, a NoSQL database or some kind of object storage. To store big amounts of data, you can use online frameworks like Hadoop or Spark which allow you to store data in multiple devices to reduce dependence on one machine. Hadoop uses HDFS to split files into large blocks and distributes them across nodes in a cluster, which means the dataset will be processed faster and more efficiently.
There are multiple ready-made systems and libraries for different languages, from Python to C++. To make a simple recommender system from scratch, the easiest way may be to try your hand on Python’s pandas, NumPy, or SciPy.
Of course, recommender systems are the heart of e-commerce. However, the most straightforward way may not be the best and showing long lines of similar products will not win customers’ loyalty. The only way to truly engage with customers is to communicate with each as an individual, but advanced and non-traditional techniques, such as deep learning, social learning, and tensor factorization based on machine learning and neural networks can also be a step forward.