
Interspeech is the world’s largest and most comprehensive conference on the science and technology of spoken language processing.
Interspeech 2017 gathered circa 2000 participants in Stockholm, Sweden and it exceeded expected capacity of the conference. There were lots of great people to to meet and to listen to Hideki Kawahara, Simon King, Jan Chrowski, Tara N. Sainath and many-many others. Papers acceptance rate traditionally was rather high at 51%. ICASSP 2017 had similar number, yet other ML-related conferences have this metrics closer to 20–30%.
Most of works can be classified to one of the following groups:
Unfortunately, posters and oral sessions overlapped, thus occasionally you had to choose from two interesting events happening at the same time or train quick walking skills travelling between Aula Magna and main building. Yet, overall it was pleasant to observe how recent hot trends from ML community carefully invade speech processing community. Examples include GANs for speech enhancement and voice conversion, usage of WaveNet-like architectures in non-TTS setting, RNN transducer etc. Also it was interesting that in case of acoustic modeling, going deeper is not always a solution. It sounds like a big difference from image-related problems where adding more layers often yields a better model.
Still, some researches do not abandon old-school approaches and invent new ways to apply DTW to various tasks.
Some notable papers:

One of key expectation is release of 16k hours of transcribed audio for Apollo missions to public domain. Vocabulary size probably won’t be huge, yet amount of recordings is on par with what is used in modern commercial ASR systems. Previous biggest available public corpus was LibriSpeech with circa 800 hours of read English. You already could train a decent ASR with that data, so what would be possible with 16 times more speech?
This year we will focus on two tutorials. The forenoon one is End-to-end models in ASR by Rohit Prabhavalkar and Tara Sainath. End-to-end models have become a hot topic in recent years.
A common feature of all of these models is that they are composed of a single neural network, which when given input acoustic frames directly outputs a probability distribution over graphemes or word hypotheses. In fact, as has been demonstrated in recent work, such end-to-end models can surpass the performance of conventional ASR systems.
The tutorial would cover the historical development of end-to-end approaches and also describe similarities and differences between popular models.
Another notable tutorial that unfortunately is going to be at the same time is Spoken dialog technology for education domain applications by Vikram Ramanarayanan, Keelan Evanini and David Suendermann-Oeft.
… tutorial will cover the state of the art in dialog technologies for educational domain applications, with a particular focus on language learning and assessment. This will include an introduction to the various components of spoken dialog systems and how they can be applied to develop conversational applications in the educational domain, as well as some advanced topics such as methods for speech scoring.
The practical part of the tutorial would be around the HALEF platform and OpenVXML. A brief search suggests that the spoken part would be based on Kaldi. Conventional ASR systems often struggle when used for non-native speech assessment, thus it would be interesting to see if authors would use some custom model or apply a standard recognizer.
In the afternoon session, we are planning to attend Information theory of deep learning tutorial by Naftali Tishby. It should be a really exciting talk from a theoretic point of view as deep learning theory is still underdeveloped. Works on this topic are usually going with rather severe simplifications like the elimination of layers of non-linearity.
Tutorial on Articulatory representations by Carol Espy-Wilson and Mark Tiede should also be of interest. Especially for e-learning applications. Manners and places of articulation are essential properties describing phonemes' pronunciation. Accurate estimation of these features should make ASR systems output less black-boxy compared to just probability distributions over phones.
Special sessions this year would cover various topics from paralinguistics to speech recognition for Indian languages.
Depending on the schedule, we’ll try to get to see the following three:
Deep neural networks: How can we interpret what they learned? It should be a nice session to check after the information theory tutorial.
Low resource speech recognition challenge for Indian languages. Being low on data is a common thing for anyone working with languages outside of the mainstream setting. Thus, any tips and tricks would be really valuable.
Spoken CALL shared task. Second edition. Core event for sampling approaches to language learning.
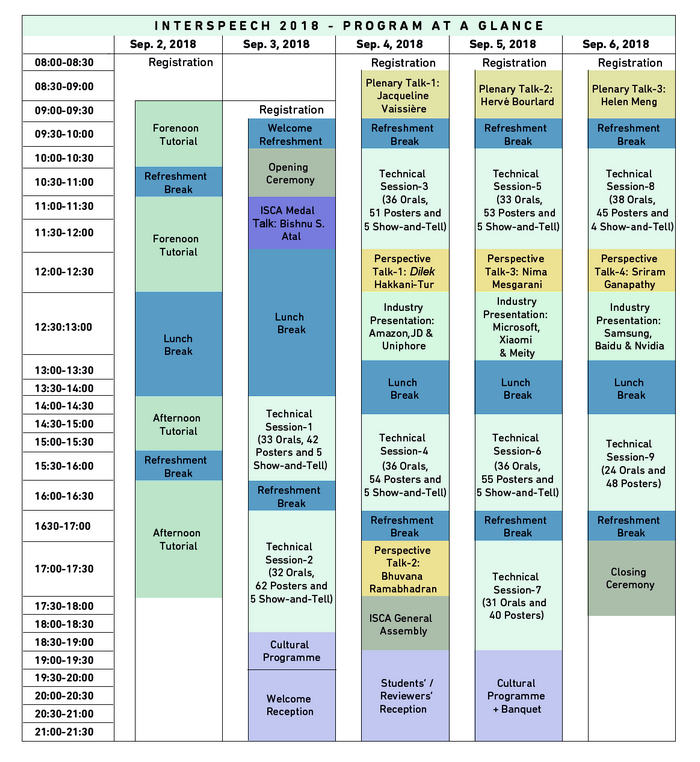
There would be hundreds of papers presented. It is impossible to cover all of them.
There is a lot of overlap between sections. Especially on day 2.
We will try to focus on the following sections:
We look forward to seeing you soon at the Interspeech 2018 in Hyderabad!


