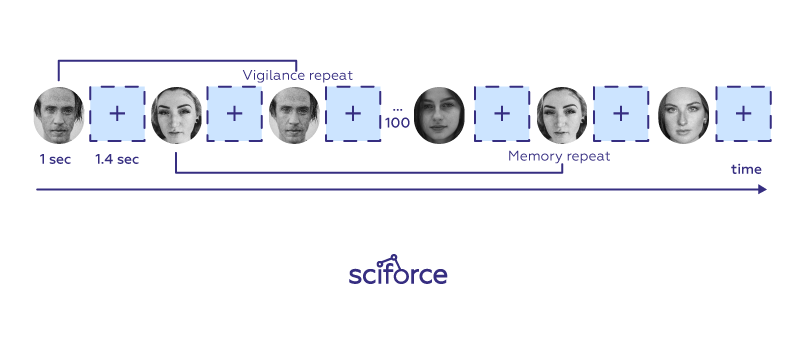
Among many things that define us as humans, there is our ability to remember things such as images in great detail, and sometimes after a single view. What is even more interesting, humans tend to remember and forget the same things, suggesting that there might be some general internal capability to encode and discard the same types of information.
What makes certain images more memorable than others? Research suggests that pictures of people, salient actions and events are more memorable than natural landscapes and images that lack distinctiveness will soon be forgotten. We can conclude that memorable and forgettable images must have certain intrinsic visual features, making some information easier to remember than others. To prove this fact, a number of computer vision projects, such as Isola 2011, Khosla 2013, Dubey 2015 managed to reliably estimate the memorability ranks of novel pictures. However, the task of predicting image memorability is quite complex: images that are memorable do not even look alike. A baby elephant, a kitchen, an abstract painting, and an old man’s face can have the same level of memorability, but no visual recognition algorithm would cluster them together. So what are the common visual features of memorable, or forgettable, images? And is it ever possible to predict which images people will remember?
Memorability is a relatively new concept in computer vision that assesses the chance that a particular image will be stored in either short-term or long-term memory. From the psychological perspective, visual memory has been a focus of attention in research for decades: for instance, thanks to psychological research, we know that different images are more or less remembered depending on many factors concerning intrinsic visual appearance and user’s context. In computer vision, researchers have revealed that color, simple image features derived from pixel statistics, and object statistics, such as number of objects, do not have strong correlation with memorability. The factors that play a role are object and scene semantics, aesthetics and interestingness, and high-level visual attributes (such as emotions, actions, movements, appearance of objects, etc.,). Besides, people tend to memorize the same images, which gives us hope that memorability is something that we can measure and predict.
It is well-known that the basis for any successful ML project is the availability of extensive and meaningful data. With more advancement in memorability research, several small datasets were developed and publicly released as a part of specific projects, including face photographs, scene categories, visualization pictures, and affective impact on image memorability.
The most important is MIT’s large-scale image memorability dataset (LaMem) containing roughly 60,000 images annotated by crowdsourcing that was published together with a memorability prediction model (MemNet) for benchmarking the task.
As the visual memory studies progress, new research has expanded to cover video memorability which also resulted in the creation of the large-scale VideoMem dataset containing 10,000 soundless videos of 7 seconds.
In recent years, a number of projects in deep learning emerged to address the task of memorability prediction. The models they introduced managed to achieve results close to human consistency (0.68), with the model called MemNet being the most prominent one.
The established idea is to treat memorability prediction as a regression task. Among a number of proposed models, MemNet developed by MIT is considered to be the most successful and well-known one. It is based on convolutional neural networks (CNN) that have proven successful in various visual recognition tasks [10, 21, 29, 35, 32]. As memorability depends on both scenes and objects, the first step in developing the model was to initialize the training using the pre-trained Hybrid-CNN [37], trained on both ILSVRC 2012 [30] and Places dataset [37]. Since memorability is a single real-valued output, the Hybrid-CNN was fine-tuned with an Euclidean loss layer.
A similar approach is used to predict memorability of videos on the basis of the VideoMem dataset.
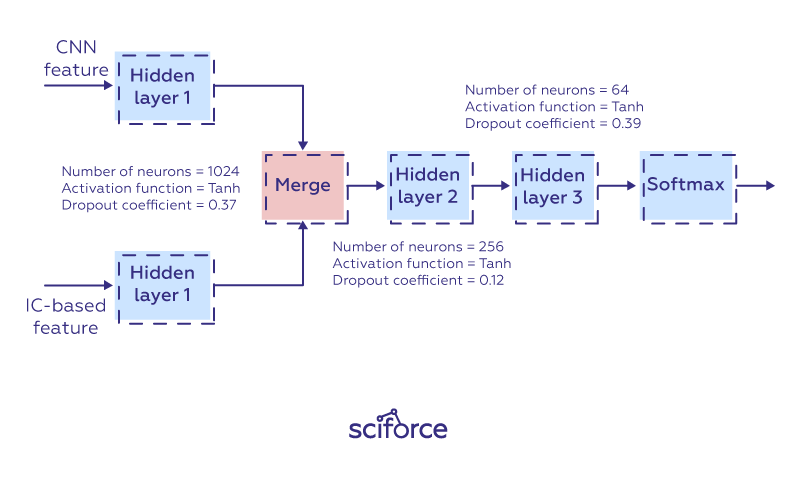
Treating memorability prediction not as a regression, but as a classification task, Technicolor developed a model that could even surpass MemNet. The model used semantic features derived from an image captioning (IC) system. Such an IC model builds an encoder comprising a CNN and a long short-term memory recurrent network (LSTM) for learning a joint image-text embedding. Thus the CNN image feature and the word2vec representation of the image caption are projected on a 2D embedding space which enforces the alignment between an image and its corresponding semantic caption that could be used to predict image memorability. A set of hyper-parameters, including the number of neurons per layer, dropout coefficient, activation function, and optimizer were selected with the Bayesian optimization library Hyperas 1 to maximize the average Spearman correlation coefficient between the predicted scores and the ground-truth scores in a 5-fold validation process.
As the ultimate goal of many computer vision tasks is to attract the user’s attention, there is much research on different factors that might increase the chance that users will look at the image or the video and gain the desired information from it. In this quest for factors that contribute to image relevance, researchers try to find out whether memorability is related to the interestingness and aesthetics of a certain image.
In general, interestingness is the power of attracting or holding one’s attention. Like memorability, it is largely studied in psychology resulting in discovering its various sides, such as novelty, uncertainty, conflict, and complexity, according to Berlyne. Also like in the case of memorability, users show a significant agreement, though finding something interesting is clearly subjective and depends on personal preferences and experiences. However, the bases of image memorability and interestingness are quite different, so there is little correlation.
Another aspect of images that is believed to be correlated with memorability is image aesthetics. Studies prove that people are more attracted to highly aesthetically attractive pictures and they choose more aesthetically appealing pictures for authentication purposes. However, aesthetics is a fairly ephemeral concept that has to do with the beauty and human appreciation of an object. Hence, though a number of computer vision papers have tried to rate, assess and predict image aesthetics, this aspect of an image is subjectively derived and aesthetic values of an image vary from subject to subject.
Hence, contrary to popular belief, unusual or aesthetically pleasing scenes are not necessarily highly memorable.
Evolution has created our brain to remember only the information relevant to our survival, reproduction, happiness, etc. That is why we share what we remember and what we forget that can be used in present-day technology to capture our attention. If machines can predict what we will remember, it can be used in various areas, including education and learning, content retrieval and search, content summarizing, storytelling, content filtering, and advertising, which make us even more efficient in our everyday lives.