The new world we live in gives us more help — and more doubts. Machines stand behind everything — and the scope of this everything is only growing. To what extent can we trust such machines? We are used to relying on them in market trends, traffic management, and maybe even in healthcare. Machines are now analysts, medical assistants, secretaries, and teachers. Are they reliable enough to work as HRs? Psychologists? What can they tell about us?
Let’s see how text analysis can analyze your soft skills and tell a potential employer whether you can join the team smoothly.
In this project, we used text analysis techniques to analyze the soft skills of young men (aged 15–24) looking for career opportunities.
What we had in mind was to perform a number of tests, or to choose the most effective one, to determine ground truth values. The tests we were experimenting with included:
The following table describes how to map MBTI and TAT test results on soft skills.
Table 1. Mapping of MBTI and TAT results on soft skills
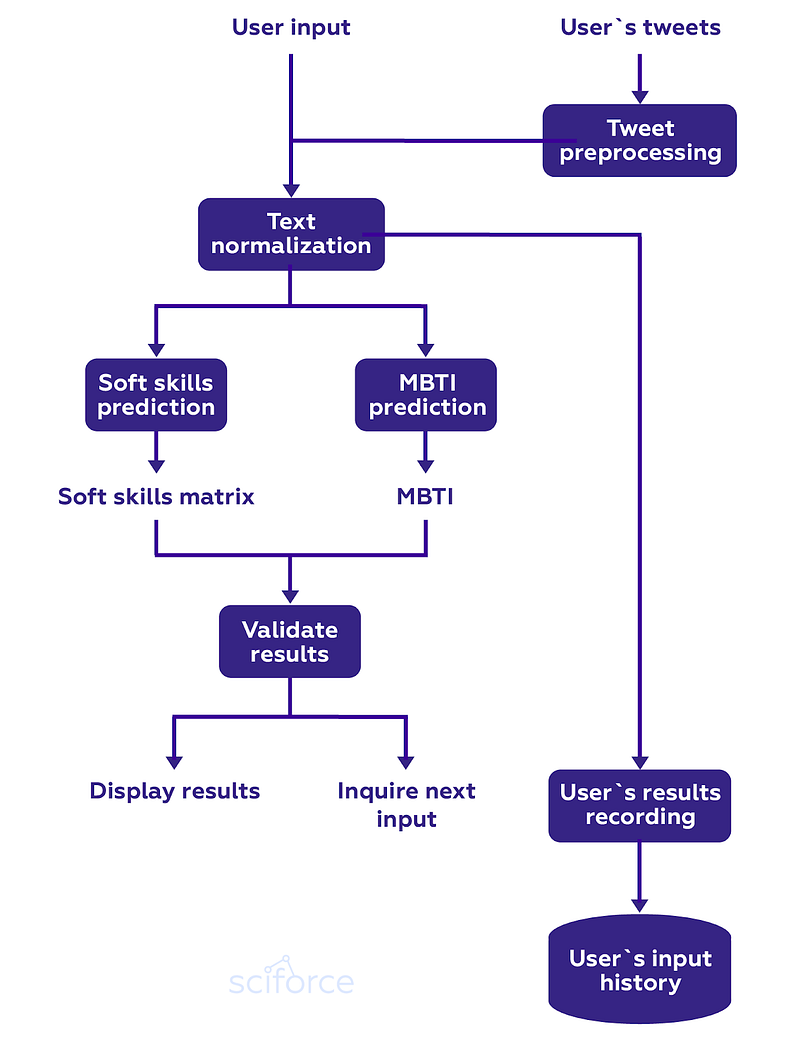
To have the fullest understanding of the user’s personality, we combine insights coming from soft skills prediction analytics and the MBTI prediction. Moreover, we keep track of the user’s past inputs and results to update our findings and to monitor possible changes in the user’s attitudes.
Any text analysis system requires a minimal amount of the user’s text at the input, as well as a minimal number of user’s tweets or FB posts (in case of linking with social media accounts). As soon as there was no publicly available labeled dataset for soft skills detection, we had to collect our own.
To quickly develop a reliable dataset we decided to expand the users’ tweets and FB posts to produce them essays and answers to the questions generated by our system.
At the registration, the user is encouraged to specify his or her social network profile (Instagram, Twitter, and Facebook profiles). The system then collects all messages authored by the user.
As the second step, the system prompts the user to write a brief essay, answering prearranged sets of questions, which should be answered in the specific order:
1. How are you doing today?
2. Please tell me about yourself
3. Tell me about a time when you demonstrated leadership.
4. Tell me about a time when you were working in a team and faced with a challenge. How did you solve this problem?
5. What is your weakness, and how do you plan to overcome it?
One more set of questions:
1. How are you doing today?
2. Please tell me about yourself
3. How do you like to spend your free time? Please, tell me about your hobbies.
4. Please tell me about some of the most memorable moments that happened to you during your study at school/college/university.
5. What is your weakness, and how do you plan to overcome it?
The questions are generated by the system based on previous data analysis.
Afterward, the user is prompted to enter their daily status, for example, as a short blog post or essay on his past day.
To make it easy for the user, we offer the following questions as a plan:
Of course, essays are not always the most convenient way to sketch your feelings about the day, and not everyone likes writing. For this, we can use a chatbot interface integrated with social media, such as Facebook Messenger.
All available texts are used as an input to the model which determines soft skills from the customers’ set.
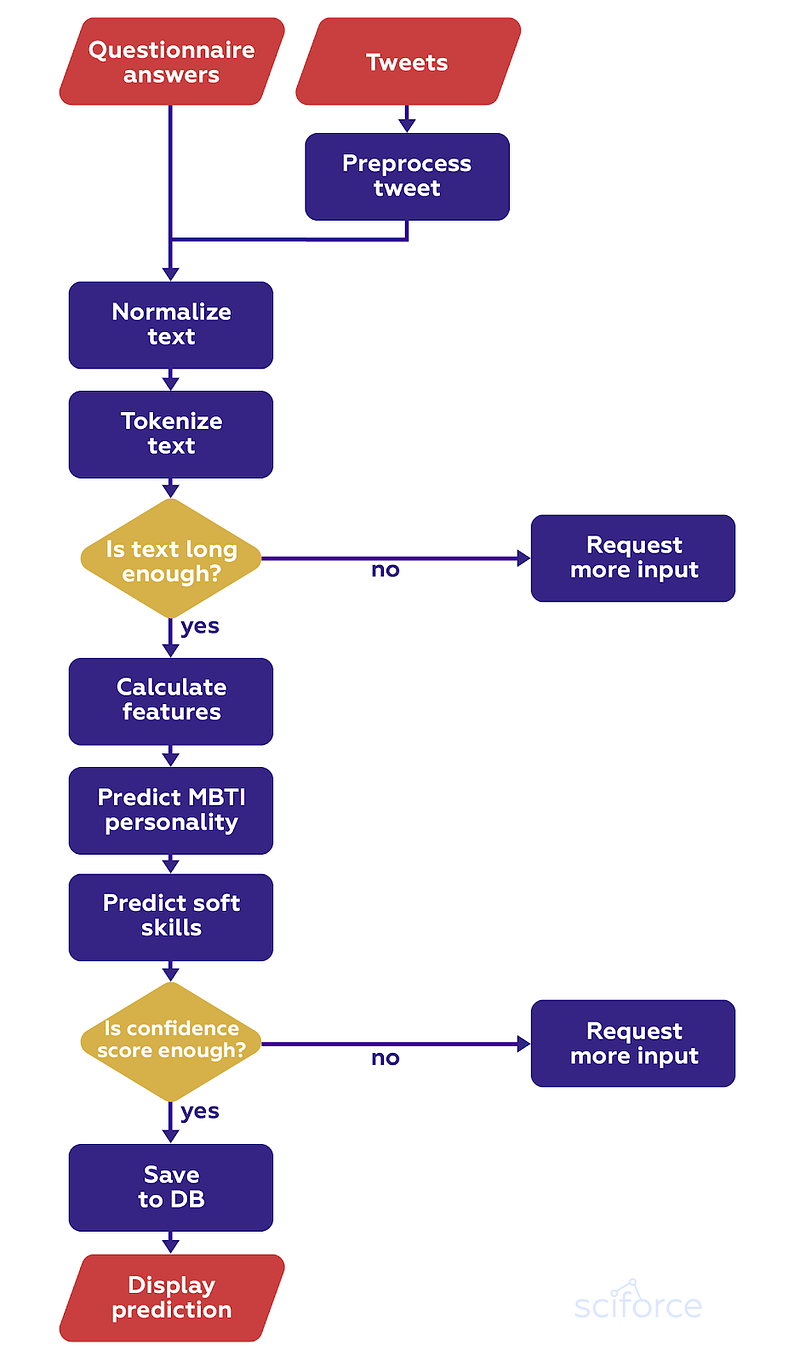
To be fed to the model for training, both questionnaire answers and collected tweets undergo preprocessing, i.e. normalization and tokenizing. At first, with the help of regular expressions, the text is freed from emoji, URLs, numbers, stop words, acronyms, etc.; HTML entities are also replaced with characters. If necessary, we complement text normalization with tokenizing.
A single module is used as an input to the model which determines soft skills from the dataset. A model’s output will be an N-dimensional vector, where N is the number of soft skills used by the system. The n-th element of the set will be a probability of the user having n-th skill. As an optional second output, we include a confidence score (depending on the model choice).
For MBTI detection, we chose the approach described by Plank, and Hovy, 2015. The authors collected a corpus of 1.5M English tweets labeled by gender and MBTI type and created a model for automatic MBTI detection. Both the corpus and the model are available, and the reported accuracy is 55–72% depending on a category (on 2000 tweets). To improve the accuracy and decrease the amount of text required for accurate detection, we additionally used the approach described in Arnoux et. al., 2017.
For soft skills detection, we chose a slightly different approach, namely, GloVE (Pennington et. al, 2014), and used the Gaussian process as a classifier.
In the next stage, we calculated the features for both MBTI and Soft Skills models. We tried to use the same features for both models in order to optimize calculations. Features were then passed to the MBTI and Soft Skills calculation models. Such features can be run in parallel if the Soft Skills model does not use the MBTI model’s output as an additional input.
At this stage, the system returns a 4-dimensional vector and an optional confidence score. Optionally, it can return 4-letter codes of Myers-Briggs personality type, e.g. “ISTJ”, “ENFP”.
It outputs an N-dimensional vector with a certain score for each soft skill (normalized to [0, 1]) and a confidence score as a second (optional) output. The system can also return an error code in case of an error (e.g. too short text, input language other than English, etc.).
This component analyzes error codes of Soft skills and MBTI prediction modules. Gaussian processes or another Bayesian model allow us to get a confidence score which is compared with a preselected threshold value. A low confidence score means that the system is not confident enough, and it cannot estimate MBTI or soft skills. In this case, an additional user’s input may be required.
Finally, the recent MBTI and soft skills assessment results are recorded in the database, including the user’s text input, the system output, and the corresponding timestamp The database stores both the initial estimation and daily updates.
To work effectively, any text analysis system has a minimal required amount of user’s text at the input, as well as a minimal number of user’s tweets or FB posts (in case we link it with social media accounts). Besides, for both soft skills and MBTI, the system can have a confidence score as an output — a floating point value from 0 to 1 (where 1 is the highest score). In case of a low confidence score (e.g. < 0.5), the user should be asked to write more detailed answers. The system will generate questions based on previous data analysis.
The second consideration is that the set of questions and the rules for their generation should be discussed. As we are not professional psychologists, we have two options to create a set of questions and rules:
We showed that Artificial Intelligence can provide deep insights into the human personality. Sentiment analysis and analysis of soft skills based on the text produced by the users are examples of tools that can be immediately used by HRs, businesses that want to monitor their employees’ attitudes and hire new specialists, as well as by candidates who want to assess and improve their chances of getting a job.