
LLMs are enabling computers to understand and generate human-like text, making them indispensable in industries ranging from customer service to content creation. The global market for LLMs is expected to skyrocket from $1.59 billion in 2023 to $259.8 billion by 2030, with North America alone projected to hit $105.545 million by 2030. The dominance of the top five LLM developers, who currently hold 88.22% of the market revenue, underscores the rapid adoption of these technologies. By 2025, an estimated 750 million applications will utilize LLMs, automating half of all digital work.
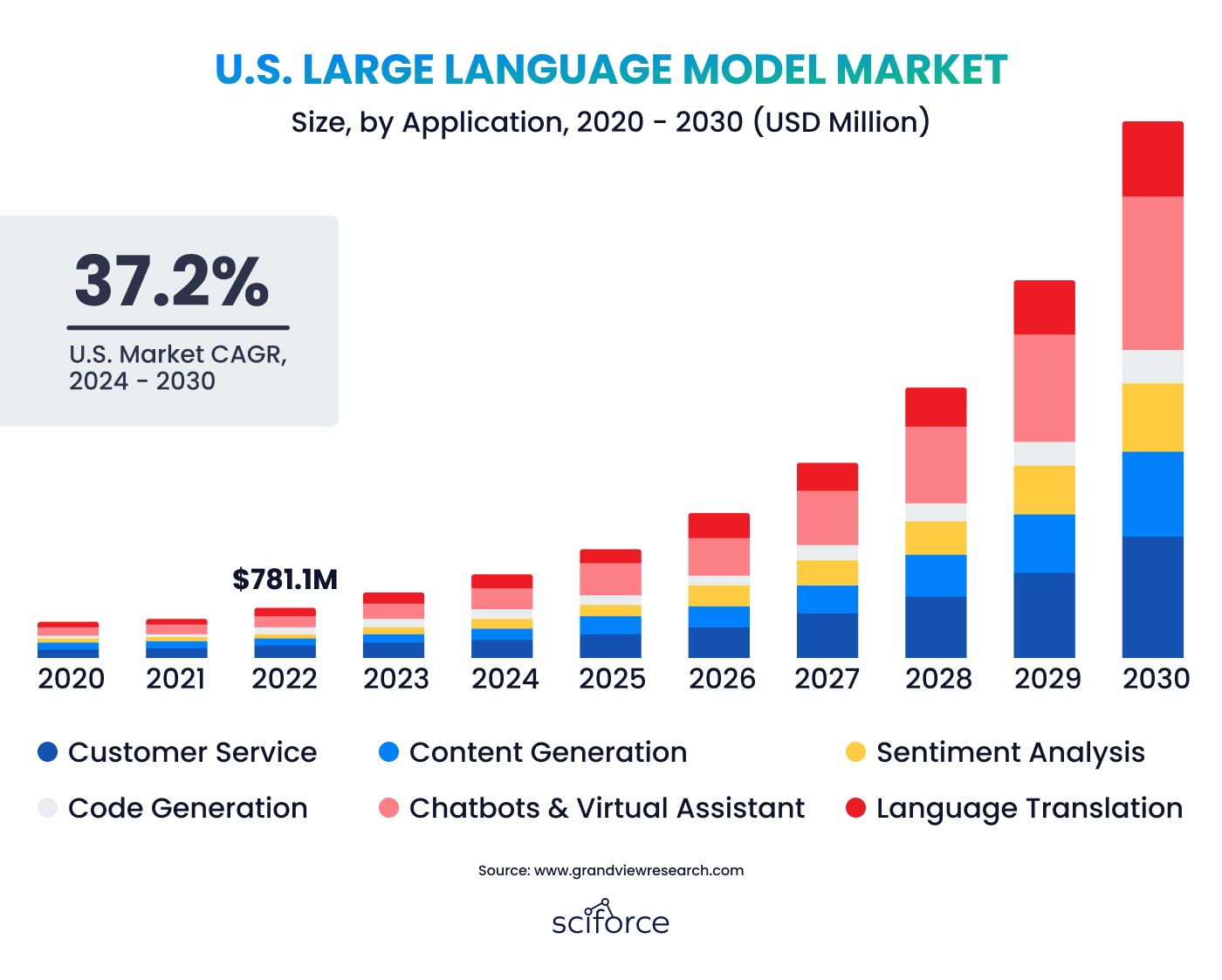
This surge in demand is driven by the need for better human-machine communication, the availability of large datasets, and a growing focus on ethical and responsible AI. As businesses seek more tailored solutions, private LLMs are becoming increasingly popular. They offer unparalleled customization, data security, and control, allowing companies to create models that align precisely with their specific needs.
At the recent AI Summit in New York, industry leaders like Google and Microsoft showcased how they are using Large Language Models (LLMs) to transform their operations. Microsoft highlighted how LLMs have enhanced their customer support systems, enabling faster and more personalized responses. Google shared examples of LLMs being used to streamline content creation, helping their teams produce high-quality materials more efficiently.
This article will walk you through the steps to build your own private LLM. Whether you are new to LLMs or want to deepen your knowledge, this guide will offer useful insights into private LLMs and why they are becoming increasingly important in the AI field.
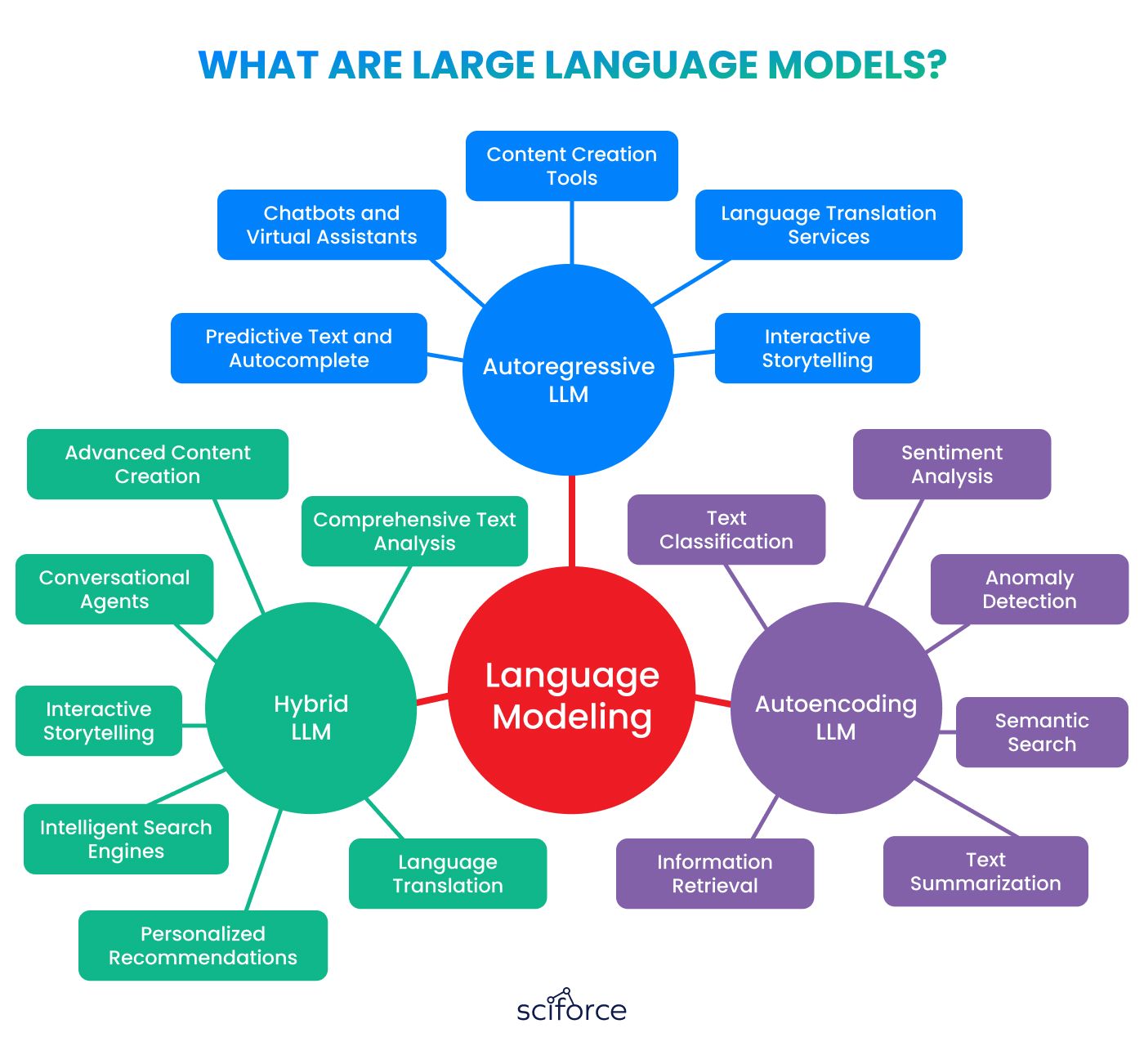
Large Language Models are advanced AI systems designed to understand and generate text that sounds like it was written by a human. These models use large amounts of data and complex neural networks, like transformers, to perform many language-related tasks. LLMs can create content, translate languages, answer questions, and hold conversations. Their wide-ranging abilities make them valuable tools in many industries, including customer service, content creation, and data analysis.
Autoregressive LLM
Autoregressive language models generate text by predicting the next word based on the previous words in a sentence. They analyze the context provided by earlier words to ensure the produced text is coherent and relevant. This method is particularly useful for natural language generation tasks:
Autoencoding LLM
Autoencoding language models focus on understanding and encoding the context of a text. They compress the input text into a simpler, lower-dimensional representation (encoding) and then reconstruct it back to its original form (decoding). This process helps the model learn the structure and meaning of the text, making it particularly effective for various analytical tasks:
Hybrid LLM
Hybrid models combine the features of both autoregressive and autoencoding models, leveraging the strengths of each approach. These models can generate text while also deeply understanding the context, making them highly versatile and suitable for complex applications.
First, an LLM is given a massive amount of text from books, articles, websites, and other sources. This process helps the model learn the rules of language, including grammar, vocabulary, and context. It’s like the model is reading millions of books to understand how language works.
Once the LLM has "read" and learned from all this text, it can perform various tasks:
- Writing:
It can generate stories, articles, or reports by predicting what comes next in a sentence based on what it has learned.
- Answering Questions:
It can answer questions by recalling information similar to how it has seen it in the texts it read.
- Having Conversations:
It can engage in conversations, responding in ways that make sense based on the context of what has been said.
For example, if you ask an LLM to write a short story about a space adventure, it will use its knowledge from the many space stories it has read to create a new, coherent story. Similarly, if you ask it to explain how photosynthesis works, it can pull together information from biology texts to give a clear explanation.
Recent LLMs, like Llama 3 and GPT-4, are trained on vast datasets—Llama 3 with 11 trillion words (15 trillion tokens) and GPT-4 with 5 trillion words (6.5 trillion tokens). Training these models involves processing trillions of tokens from diverse sources, including up to 140 trillion from social media and 1,200 trillion from private data, ensuring a comprehensive understanding of language across various contexts.
The datasets used typically range from hundreds of terabytes to multiple petabytes, providing a rich resource for learning intricate language patterns, vocabulary, idiomatic expressions, and contextual usages. High-quality datasets are curated to include well-written and informative texts, ensuring the model encounters a wide variety of sentence structures.
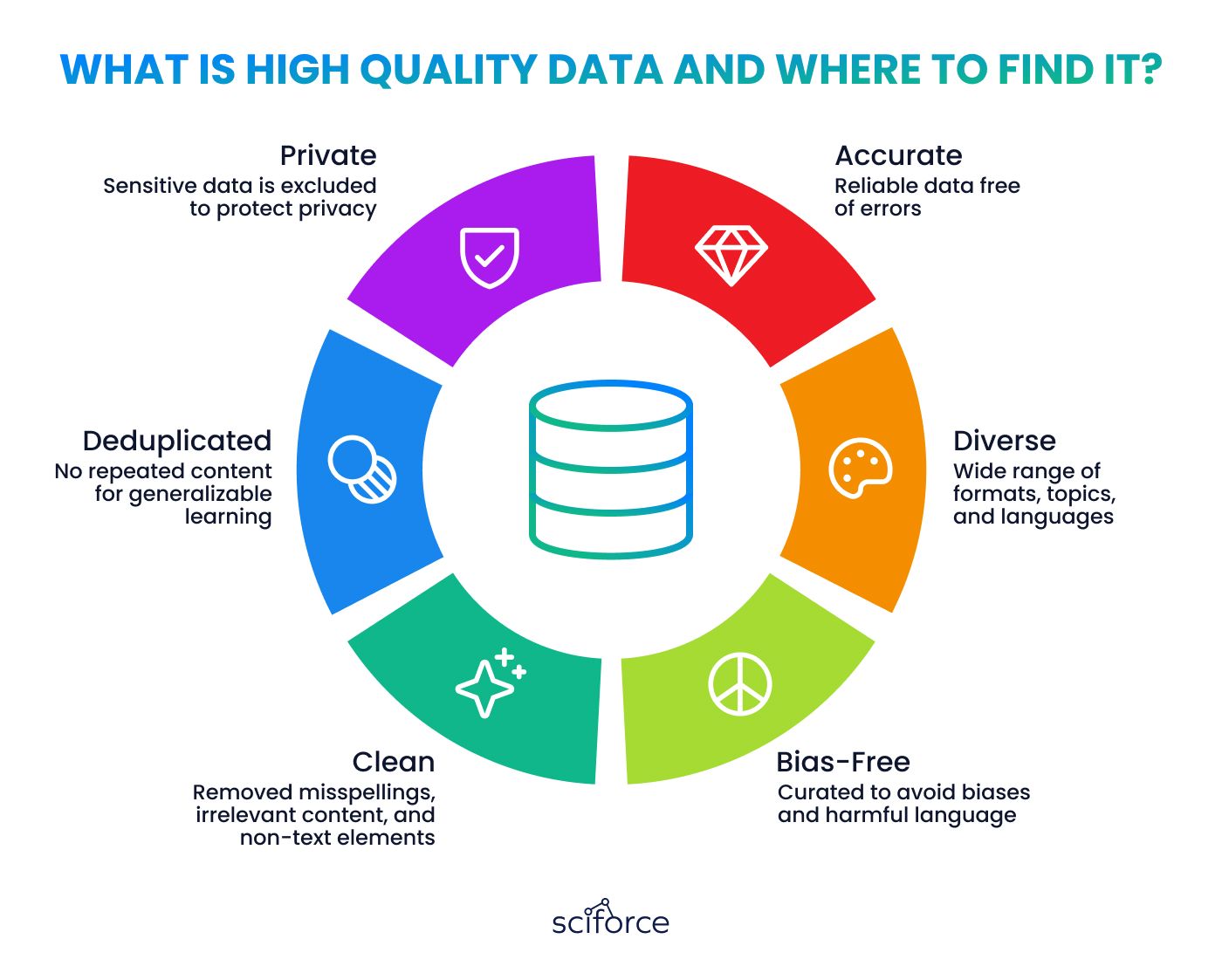
- Web Data:
FineWeb (not fully deduplicated for better performance, entirely English), Common Crawl (55% non-English)
- Code:
Publicly Available Code from all the major code hosting platforms
- Academic Texts:
Anna’s Archive, Google Scholar, Google Patents
- Books:
Google Books, Anna’s Archive
- Court Documents:
RECAP archive (USA), Open Legal Data (Germany)
When curating and preprocessing data for LLMs, ensuring that the data is clean, accurate, and well-structured is just the beginning. The next critical steps involve transforming this pre-processed data into a format that the LLM can effectively understand and learn from. This is where tokenization, embedding, and attention mechanisms come into play:
Tokenization
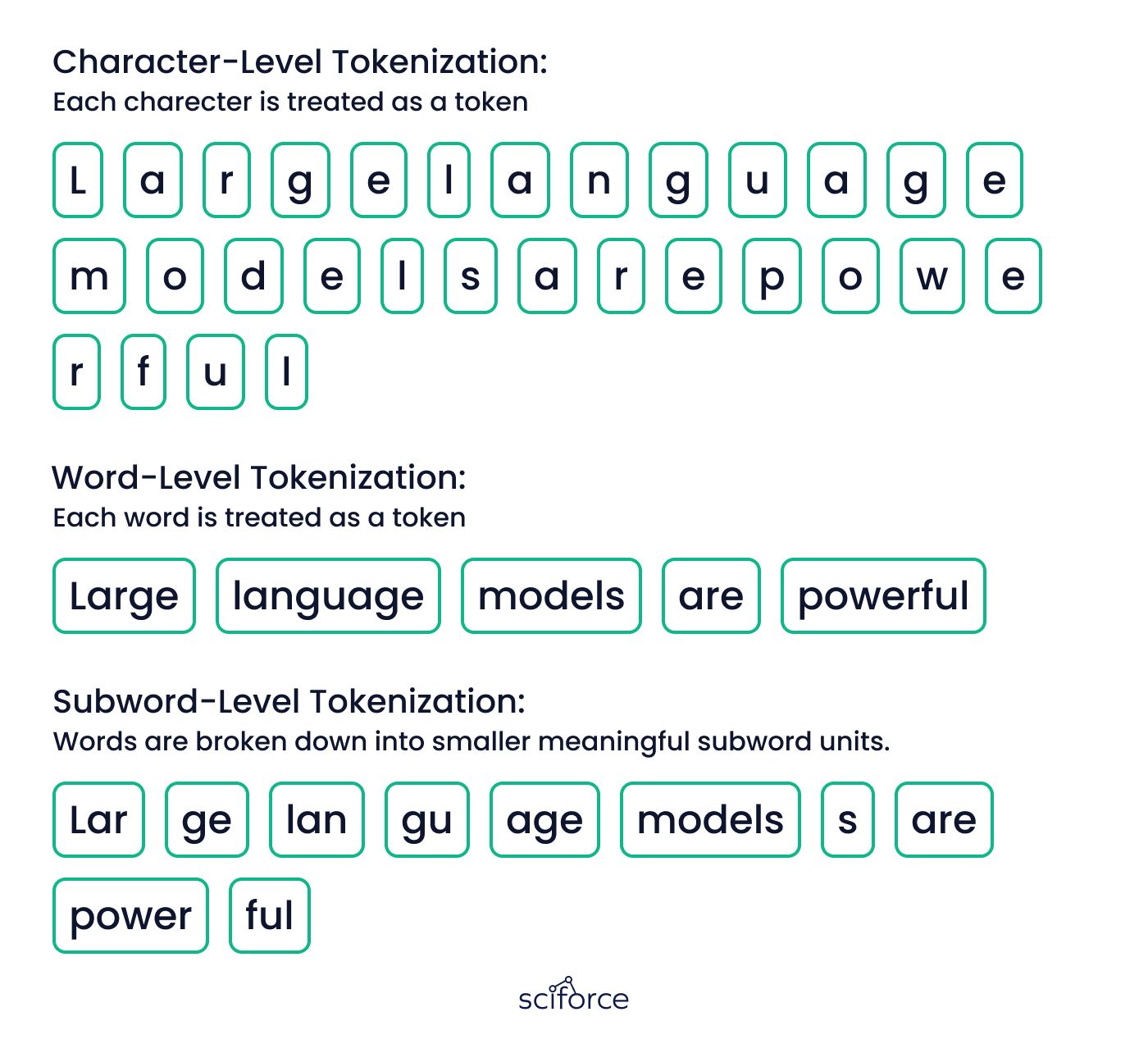
Tokenization is the process of breaking down text into smaller pieces called tokens, which can be words, subwords, or individual characters. For example, the sentence "Large language models are powerful" can be tokenized into individual words: ["Large", "language", "models", "are", "powerful"]. By breaking down text into tokens, the model can handle various text lengths, manage a manageable set of words or subwords, and understand the context of each token within a sentence, improving the accuracy of tasks like translation or text generation.
Embedding
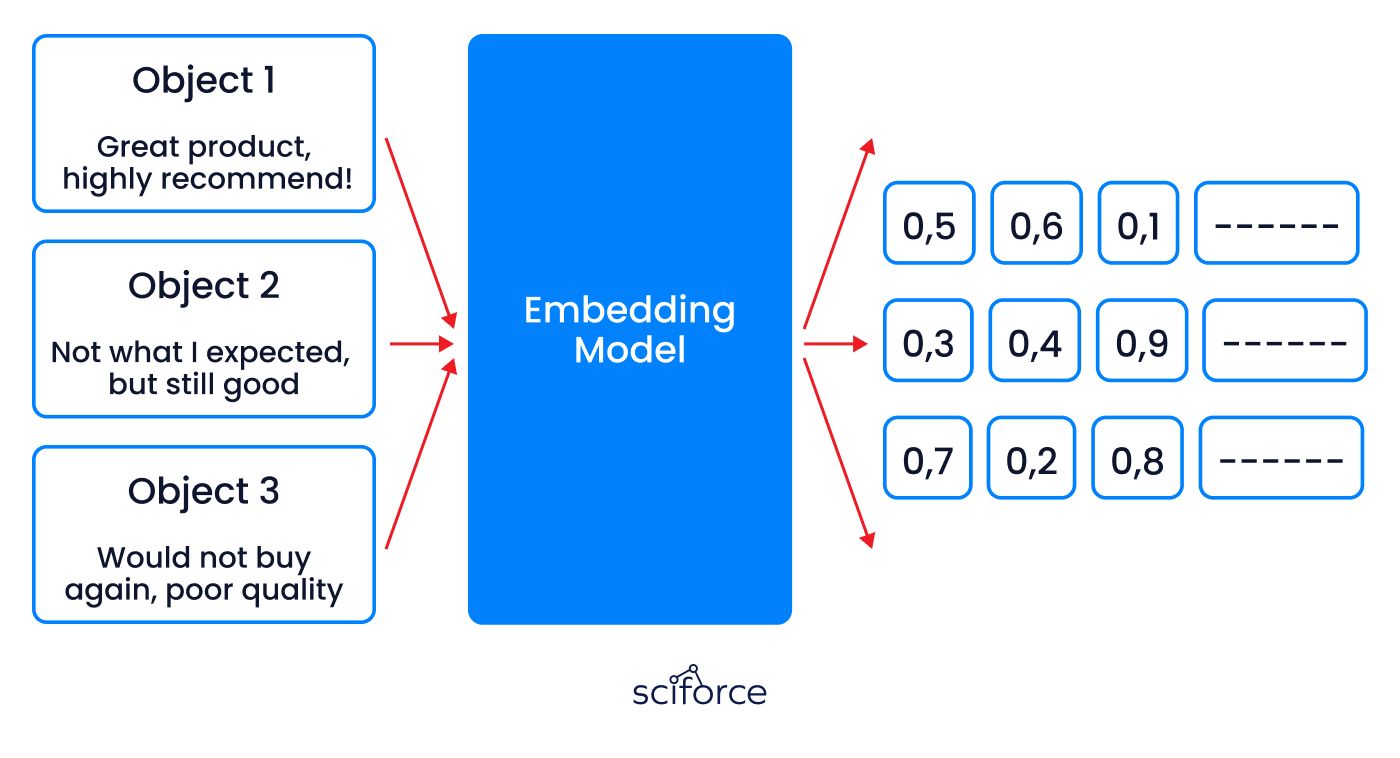
Embedding is a way to turn customer reviews into numbers so a computer can understand them. Each review gets a unique set of numbers called a vector that captures its sentiment and meaning. For example, the review "Great product, highly recommended!" might become [0.9, 0.8, ...], and "Not what I expected, but still good." might become [0.6, 0.5, ...]. These numbers help the computer see that the first review is more positive, while the second is more neutral. This process is important because it helps the computer analyze customer sentiment, categorize reviews, and improve product recommendations based on customer feedback.
Attention
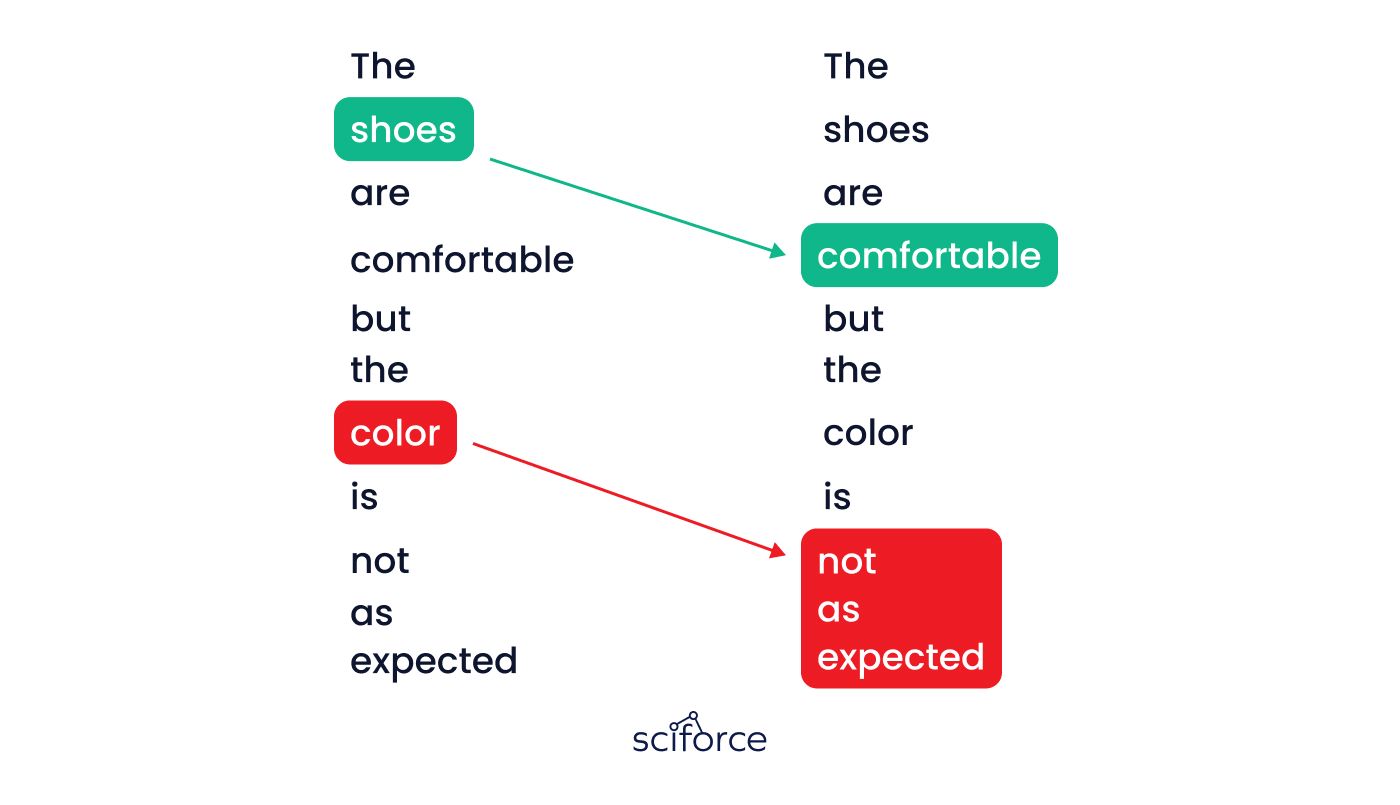
Attention is a mechanism that helps the model focus on the most important parts of a sentence. It makes sure the model understands which words matter most to get the meaning right. For example, in the review "The product quality is excellent, but the delivery was delayed," attention helps the model identify that "quality is excellent" reflects positive feedback on the product, while "delivery was delayed" highlights a negative aspect related to the service. This process is crucial for understanding the overall sentiment of the review, allowing the model to provide accurate summaries, categorize reviews, or suggest improvements based on customer feedback.
After forward propagation, the model’s predictions are assessed by comparing them to the true labels using a specific loss function. This step is essential for determining how accurately the model is performing its task.
The loss function calculates the difference between the predicted output and the actual target, converting this difference into a single numerical value known as the "loss" or "error." For instance, in classification tasks, cross-entropy loss is commonly used. This function evaluates how closely the predicted probabilities match the true class labels, with a focus on penalizing incorrect predictions more heavily.
The resulting scalar value indicates the model’s performance: a higher loss value suggests that the model’s predictions are significantly off, while a lower loss value indicates that the predictions are closer to the actual targets.
Hyperparameter tuning is critical for controlling the training process in neural networks, including LLMs. Key hyperparameters like learning rate and batch size directly impact how the model learns:
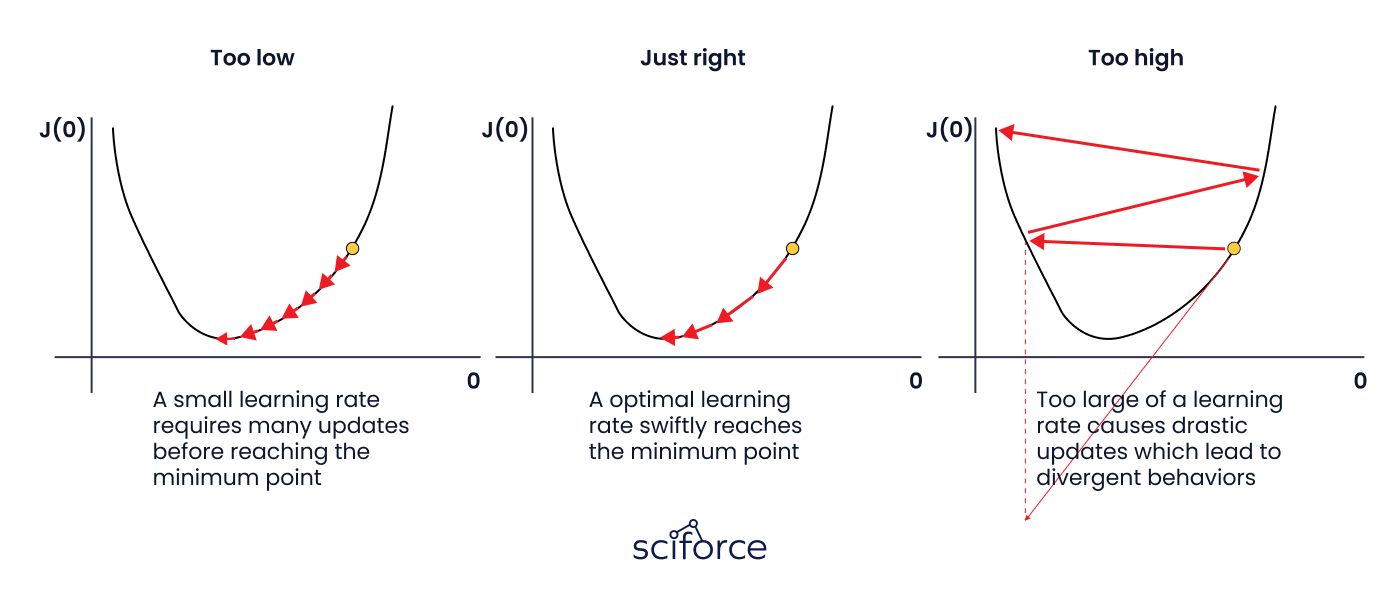
- Learning Rate: Determines the size of weight updates during training. Too high, and the model may converge too quickly or diverge; too low, and training becomes inefficient.
- Batch Size: Refers to the number of samples processed in each iteration. Larger batches stabilize training but require more memory, while smaller batches introduce variability but are less resource-intensive.
Tuning these hyperparameters is essential to ensure the training loop converges effectively, leading to better model performance and efficiency. Proper tuning reduces training time and enhances model accuracy.
As neural networks and LLMs grow in size, managing computational resources efficiently becomes essential. Parallelization and resource management techniques directly support key stages of the training process by optimizing how these processes are executed.
These techniques allow the training loop to scale effectively, handle large models and datasets, and support aggressive hyperparameter tuning without overwhelming available resources. By optimizing resource use, they ensure that the entire training process remains efficient and effective.
As training progresses, metrics like loss and accuracy are monitored after each epoch to guide adjustments and prevent issues such as overfitting or underfitting. Training neural networks, including LLMs, involves repeatedly running through training loop across multiple iterations and epochs to gradually improve the model:
Through repeated iterations and multiple epochs, the model’s parameters are fine-tuned, leading to progressively better performance. This process of continuous refinement ensures that the model becomes increasingly accurate and robust, making it well-prepared for deployment in real-world tasks.
After training your Large Language Model (LLM), it’s crucial to evaluate its performance to ensure it meets the desired standards. Industry-standard benchmarks are commonly used to measure various aspects of LLM capabilities:
MMLU (Massive Multitask Language Understanding):
A comprehensive benchmark that measures the model’s natural language understanding across a broad range of subjects. This benchmark is widely used to assess the general linguistic and reasoning capabilities of LLMs.
GPQA (General Purpose Question Answering):
Focuses on evaluating the model's ability to handle diverse and complex question-answering tasks. This benchmark tests the LLM’s proficiency in providing accurate, contextually relevant answers across various domains.
MATH:
Specifically designed to test the model’s mathematical reasoning skills, the MATH benchmark involves solving multi-step problems that require both calculation and logical reasoning. It’s essential for evaluating the model's ability to understand and solve math-related tasks.
HumanEval:
Assesses the model's capability in generating functional and correct code. This benchmark is critical for evaluating models intended for coding tasks, with focus on accuracy and functionality.
For those developing LLMs from scratch, advanced benchmarks and platforms like Arena can be used. On Arena, anyone can pose questions to two anonymous LLMs and determine which one answers better, influencing the LLMs' rankings. This approach provides a more dynamic, user-driven evaluation. Moreover, companies like OpenAI, Anthropic, and others regularly release benchmark results for their models. These include:
OpenAI:
Benchmarks like MMLU, GPQA, MATH, and HumanEval are commonly released to showcase the model's capabilities across various tasks .
Anthropic's Claude 3 Family:
Claude 3 models set new industry benchmarks across a range of cognitive tasks, further pushing the boundaries of what LLMs can achieve.
When fine-tuning an LLM for specific business applications, the evaluation metrics are dictated by the task. For example, if the model is used in a medical setting to match disease descriptions with corresponding codes, accuracy might be the primary metric. Fine-tuning typically involves adapting the model to specific prompts and contexts, and the chosen metric should reflect the business objectives.
After training your LLM, evaluating its performance is essential. While specific benchmarks like ARC and HellaSwag assess technical abilities, broader conversational metrics are crucial for interactive applications. These metrics, such as engagement, coherence, and context awareness, measure how effectively the model engages with users and maintains conversation quality.
The following image highlights these key conversational metrics, providing a snapshot of the model's ability to deliver a seamless and effective user experience.

Evaluating your LLM doesn’t stop after the initial assessment. Continuous monitoring is essential to ensure that the model maintains its performance over time, especially as new data becomes available or as the model is deployed in different contexts.
As new data is introduced, periodically retrain and fine-tune the model to keep it accurate and relevant. Regularly test the model’s performance using the established benchmarks to catch any declines in accuracy or effectiveness early.
Building a private Large Language Model is a challenging but highly rewarding process that offers unmatched customization, data security, and performance. By carefully curating data, choosing the right architecture, and fine-tuning the model, you can create a powerful tool tailored to your specific needs.
This guide has provided a roadmap developing an LLM, from data processing to continuous evaluation. By following these steps, you can build an LLM that excels in its tasks and adapts to evolving demands, giving your organization a competitive edge.
If you're ready to build your own private LLM or need expert guidance to navigate this process, contact us for a free consultation.
Also, we're thrilled to announce a free webinar on how LLMs can improve your business on September 26th at 5 PM GMT+3. You will have the opportunity to ask our expert, Volodymyr Sokhatskyi, about LLM development or opportunities for your industry. To find out more information about the event and register your spot you can here.


