In my childhood, one of the funniest interactions with a computer was to make it read a fairy tale. You could copy a text into a window and soon listen to a colorless metallic voice stumble through commas and stop weaving a weirdly accented story. At those times it was a miracle.
Nowadays the goal of TTS — the Text-to-Speech conversion technology — is not to simply have machines talk, but to make them sound like humans of different ages and genders. In perspective, we’ll be able to listen to machine-voiced audiobooks and news on TV or to communicate with assistants without noticing the difference.
How it can be achieved and the main competitors in the field — read in our post.
As a rule, the quality of TTS system synthesizers is evaluated from different aspects, including intelligibility, naturalness, and preference of the synthetic speech [4], as well as human perception factors, such as comprehensibility [3].
Intelligibility: the quality of the audio generated, or the degree of each word being produced in a sentence**.**
Naturalness: the quality of the speech generated in terms of its timing structure, pronunciation, and rendering emotions.
Preference: the listeners’ choice of the better TTS; preference and naturalness are influenced by the TTS system, signal quality, and voice, in isolation and in combination.
Comprehensibility: the degree to of received messages are understood.
Developments in Computer Science and Artificial Intelligence influence the approaches to speech synthesis that have evolved through the years in response to recent trends and new possibilities in data collection and processing. While for a long time, the two main methods of Text-to-Speech conversion are concatenative TTS and parametric TTS, the Deep Learning revolution has added a new perspective to the problem of speech synthesis, shifting the focus from human-developed speech features to fully machine-obtained parameters [1,2].
Concatenative TTS relies on high-quality audio clip recordings, which are combined together to form the speech. In the first step voice actors are recorded saying a range of speech units, from whole sentences to syllables that are further labeled and segmented by linguistic units from phones to phrases and sentences forming a huge database. During speech synthesis, a Text-to-Speech engine searches such database for speech units that match the input text, concatenates them together, and produces an audio file.
Pros
- High quality of audio in terms of intelligibility;
- Possibility to preserve the original actor’s voice;
Cons
- Such systems are very time-consuming because they require huge databases, and hard-coding the combination to form these words;
- The resulting speech may sound less natural and emotionless, because it is nearly impossible to get the audio recordings of all possible words spoken in combinations of emotions, prosody, stress, etc.
Examples:
Singing Voice Synthesis is the type of speech synthesis that fits the best opportunities of concatenative TTS. With the possibility to record a specific singer, such systems are able to preserve the heritage by restoring records of stars of the past days, as in Acapella Group, as well as to make your favorite singer perform another song according to your liking, as in Vocaloid.
The formant synthesis technique is a rule-based TTS technique. It produces speech segments by generating artificial signals based on a set of specified rules mimicking the formant structure and other spectral properties of natural speech. The synthesized speech is produced using an additive synthesis and an acoustic model. The acoustic model uses parameters like, voicing, fundamental frequency, noise levels, etc that vary over time. Formant-based systems can control all aspects of the output speech, producing a wide variety of emotions and different tone voices with the help of some prosodic and intonation modeling techniques.
Pros
- Highly intelligible synthesized speech, even at high speeds, avoiding the acoustic glitches;
- Less dependant on a speech corpus to produce the output speech;
- Well-suited for embedded systems, where memory and microprocessor power are limited.
Cons
- Low naturalness: the technique produces artificial, robotic-sounding speech that is far from the natural speech spoken by a human.
- Difficult to design rules that specify the timing of the source and the dynamic values of all filter parameters for even simple words
Examples
The formant synthesis technique is widely used for mimicking the voice features that take speech as input and find the respective input parameters that produce speech, mimicking the target speech. One of the most famous examples is espeak-ng, an open-source multilingual speech synthesis system based on the Klatt synthesizer. This system is included as the default speech synthesizer in the NVDA open-source screen reader for Windows, Android, Ubuntu, and other Linux distributions. Moreover, its predecessor eSpeak was used by Google Translate for 27 languages in 2010.
To address the limitations of concatenative TTS, a more statistical method was developed. The idea lying behind it is that if we can make approximations of the parameters that make the speech, we can train a model to generate all kinds of speech. The parametric method combines parameters, including fundamental frequency, magnitude spectrum, etc., and processes them to generate speech. In the first step, the text is processed to extract linguistic features, such as phonemes or duration. The second step requires extraction of vocoder features, such as cepstra, spectrogram, fundamental frequency, etc., that represent some inherent characteristic of human speech and are used in audio processing. These features are hand-engineered and, along with the linguistic features are fed into a mathematical model called a Vocoder. While generating a waveform, the vocoder transforms the features and estimates parameters of speech like phase, speech rate, intonation, and others. The technique uses Hidden Semi-Markov models — transitions between states still exist, and the model is Markov at that level, but the explicit model of duration within each state is not Markov.
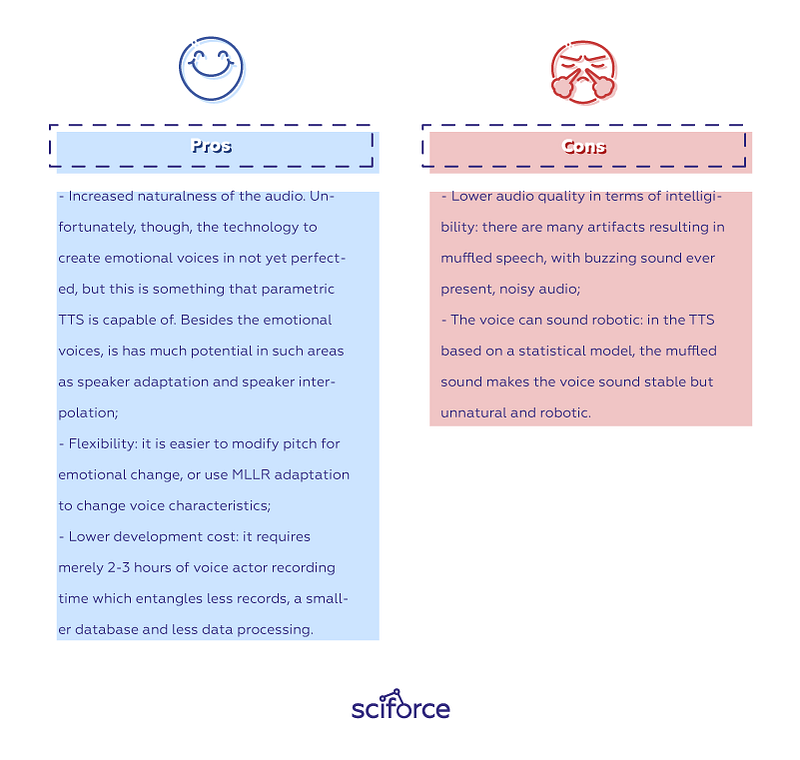
Pros:
- Increased naturalness of the audio. Unfortunately, though, the technology to create emotional voices is not yet perfected, but this is something that parametric TTS is capable of. Besides the emotional voices, it has much potential in such areas as speaker adaptation and speaker interpolation;
- Flexibility: it is easier to modify pitch for emotional change, or use MLLR adaptation to change voice characteristics;
- Lower development cost: it requires merely 2–3 hours of voice actor recording time which entangles fewer records, a smaller database, and less data processing.
Cons:
- Lower audio quality in terms of intelligibility: there are many artifacts resulting in muffled speech, with buzzing sound ever present, noisy audio;
- The voice can sound robotic**:** in the TTS based on a statistical model, the muffled sound makes the voice sound stable but unnatural and robotic.
Examples:
Though first introduced in the 1990s, the parametric TTS engine became popular around 2007, with Festival Speech Synthesis System from the University of Edinburgh and Carnegie Mellon University’s Festvox being examples of such engines lying in the heart of speech synthesis systems, such as FreeTTS.
The DNN (Deep Neural Network) based approach is another variation of the statistical synthesis approaches that are used to overcome the inefficiency of decision trees used in HMMs to model complex context dependencies. A step forward and an eventual breakthrough was letting machines design features without human intervention. The features designed by humans are based on our understanding of speech, but it is not necessarily correct. In DNN techniques, the relationship between input texts and their acoustic realizations is modeled by a DNN. The acoustic features are created using maximum likelihood parameter generation trajectory smoothing. Features obtained with the help of Deep Learning, are not human readable, but they are computer-readable, and they represent data required for a model.
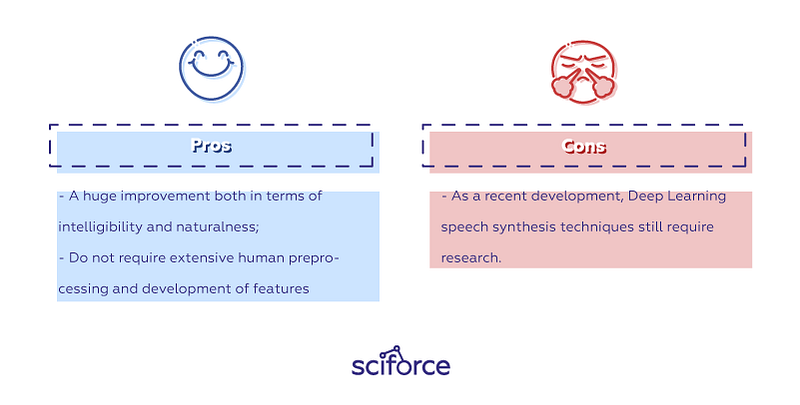
Pros
- A huge improvement both in terms of intelligibility and naturalness;
- Do not require extensive human preprocessing and development of features
Cons
- As a recent development, Deep Learning speech synthesis techniques still require research.
Examples:
It is the deep learning technique that dominates the field now, being at the core of practically all successful TTS systems, such as WaveNet, Nuance TTS, or SampleRNN.
Nuance TTS and Sample RNN are two systems that rely on recurrent neural networks. SampleRNN, for instance, uses a hierarchy of Recurrent Layers that have different clock rates to process the audio. Multiple RNNs form a hierarchy, where the top level takes large chunks of inputs, processes them, and passes them to the lower level that processes smaller chunks and so on through the bottom level that generates a single sample. The techniques render far less intelligible results but work fast.
WaveNet, being the core of Google Could Text-to-Speech, is a fully convolutional neural network, which takes digitized raw audio waveform as input, which then flows through these convolution layers and outputs a waveform sample. Though close to perfect in its intelligibility and naturalness, WaveNet is unacceptably slow (the team reported that it takes around 4 minutes to generate 1 second of audio).
Finally, the new wave of end-to-end training brought Google’s Tacotron model that learns to synthesize speech directly from (text, audio) pairs. It takes characters of the text as inputs, passes them through different neural network submodules, and generates the spectrogram of the audio.
As we can see, the evolution of speech synthesis increasingly relies on machines in both determinations of the necessary features and processing them without the assistance of human-developed rules. This approach improves the overall quality of the audio produced and significantly simplifies the data collection and preprocessing process. However, each approach has its niche, and even less efficient concentrative systems may become the optimal choice depending on the business needs and resources.
King, Simon. “A beginners ’ guide to statistical parametric speech synthesis.” (2010).
Kuligowska, K, Kisielewicz, P. and Wlodarz, A. (2018) Speech synthesis systems: disadvantages and limitations, International Journal of Engineering & Technology**,** [S.l.], v. 7, n. 2.28, p. 234–239.
Pisoni, D. B. et al., “Perception of synthetic speech generated by rule,” in Proceedings of the IEEE, 1985, pp. 1665–1676.
Stevens, C. et al., “Online experimental methods to evaluate text-to-speech (TTS) synthesis: effects of voice gender and signal quality on intelligibility, naturalness and preference,” Computer Speech and Language, vol. 19, pp. 129–146, 2005.