
Impaired speech varies in pronunciation, pacing, and clarity, making standard datasets inadequate. A specialized system was needed to collect and annotate speech, handling unclear words, repetitions, and varying complexity while ensuring quality data for both structured and spontaneous speech.
Accurate speech recognition is challenging for irregular speech patterns, especially with conditions like Parkinson’s and cerebral palsy. Standard systems struggle with variability, making personalization essential. A three-step process—pre-training, general training, and user fine-tuning—enhances recognition while optimizing efficiency.
Protecting user data while improving speech recognition requires strict privacy controls. Real-world speech may contain personally identifiable information (PII), demanding secure handling, regular audits, and clear user consent policies. Ethical and legal challenges also arise around data ownership and monetization, requiring careful compliance management.
Early lightweight models ensured privacy but lacked the power for free-form speech. Cloud-based processing improved accuracy but introduced latency, infrastructure costs, and security risks. Ethical concerns around voice cloning and data ownership further complicated deployment.
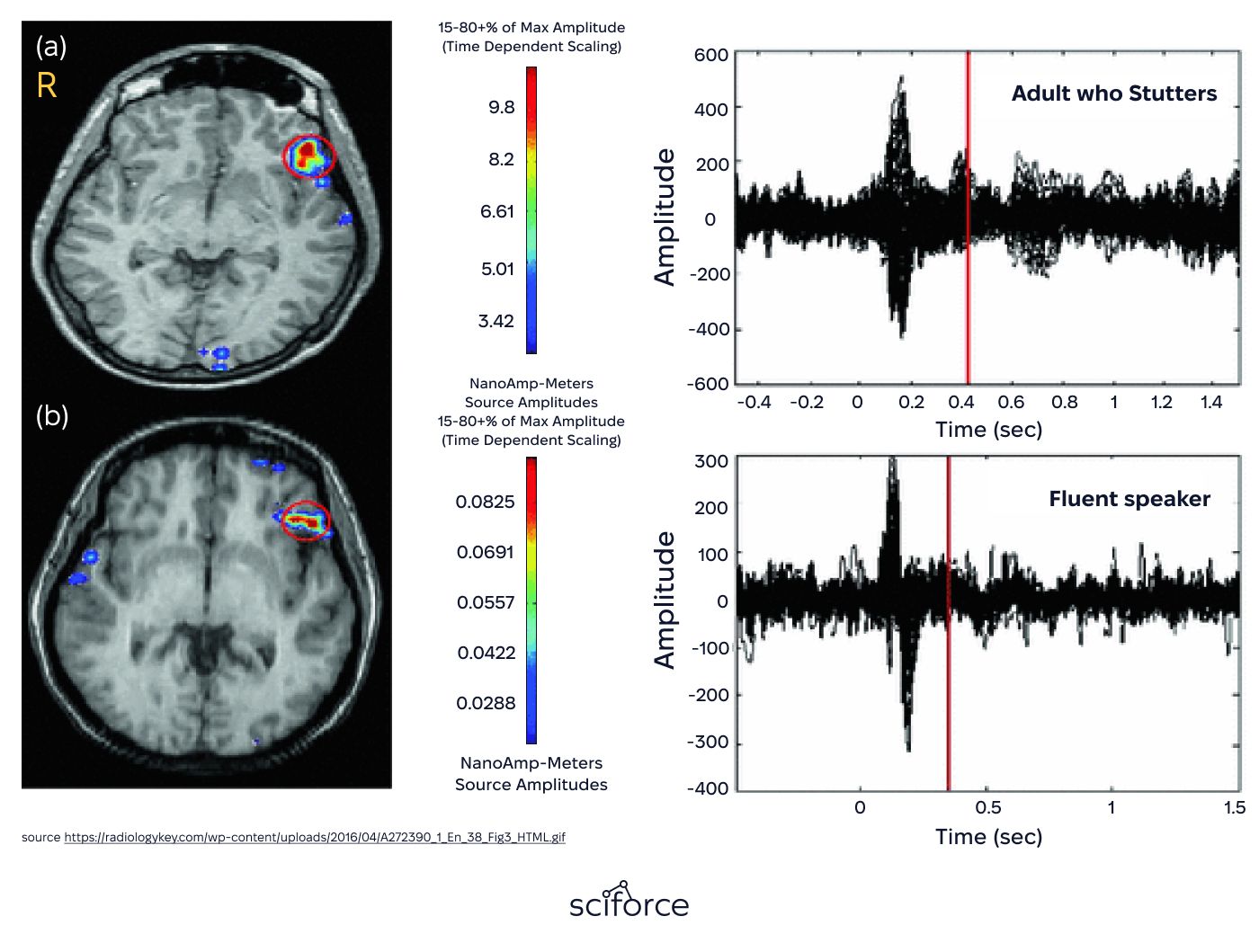
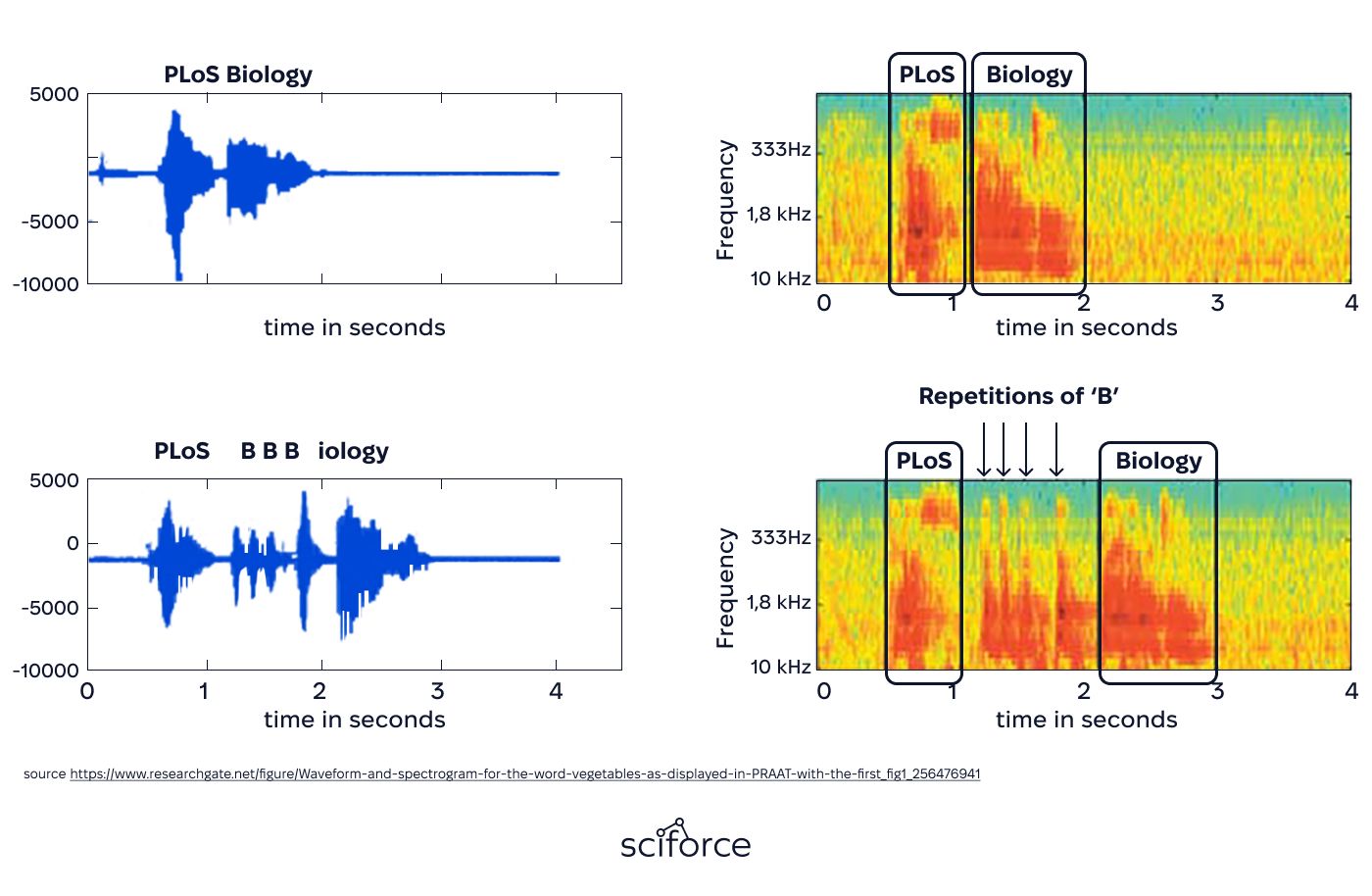
Standard speech recognition models fail to accurately process impaired speech, with error rates reaching 70-80% due to difficulties in recognizing unclear pronunciation, atypical pacing, and inconsistent speech patterns. Achieving higher accuracy requires specialized training to handle these variations effectively.
To develop a model that effectively recognizes impaired speech, a multi-stage training process was implemented:
The data collection and annotation infrastructure includes a web-based system that facilitates speech data gathering and refinement.
Users contribute personalized speech samples for training, while managers oversee dataset complexity to ensure diverse input. Annotators review and refine transcriptions through a multi-step validation process, improving accuracy.
The system also refines datasets by filtering out incomplete words, repeated phrases, and unclear pronunciations, enhancing recognition quality. Additionally, dataset complexity control allows for adaptation to varying levels of speech impairments, ensuring a diverse and high-quality training dataset.
Speech impairments vary widely between individuals, requiring a system that adapts over time. The model achieves this through progressive personalization:
The system adapts to individual speech characteristics by adjusting for stuttering, mispronunciations, and variations in speech pacing. It also customizes recognition based on user habits, refining accuracy for frequently used phrases, whether for home automation commands like "turn on the lights" or professional dictation in legal and medical fields.
To ensure data security and user privacy while maintaining high performance, the system integrates on-device and cloud-based processing strategically. On-device models process real-time commands locally, minimizing data exposure and enhancing privacy. For free-form speech transcription, cloud-based models improve recognition accuracy while optimizing latency and infrastructure costs.
To protect user data, the system implements strict privacy measures, including regular audits for compliance, PII filtering before data is stored or used for training, and explicit user consent mechanisms to ensure transparency.
Converts spoken input into real-time text for document filling, messaging, and hands-free writing. It integrates with Google Docs and other tools, enabling direct dictation, editing, and formatting for accessibility and efficiency.
Recognizes impaired or unclear speech and repeats it in a clearer, more natural voice for improved communication. It helps users be better understood in conversations, virtual meetings, and assistive communication devices.
Allow users to train the system to recognize personalized phrases for hands-free control of devices, apps, and automation tasks. It can also function as a smart assistant replacement, enabling voice-activated home automation and workflow management.
Processes structured commands and free-form speech, enabling natural conversations without predefined phrases. It allows fluid speech input for virtual assistants, real-time transcription, and hands-free interactions.
Personalized Speech Model adapts to individual pronunciation, pacing, and speech patterns, improving accuracy through a three-stage process: pre-training on large datasets, general training with scripted and natural speech, and fine-tuning for user-specific adaptation.
Ensures secure speech recognition with on-device processing for real-time commands and cloud-based transcription for complex speech, balancing latency and security. It includes PII filtering to remove sensitive data and user consent management for transparent data collection and usage.
Model Training and Development uses self-supervised pre-training on large-scale datasets (Wav2vec, WavLM) to extract speech patterns without labeled transcriptions. It follows a multi-stage pipeline:
A dedicated system was created to gather and refine speech data from individuals with speech impairments, ensuring the model can recognize different speech patterns accurately. Web-based tools support this process, allowing users to record speech samples for training, managers to adjust dataset complexity based on speech difficulty, and annotators to review and refine transcriptions for accuracy.
To improve recognition, annotation rules help identify unclear pronunciation, repeated words, and incomplete speech, filtering out inconsistencies while keeping important variations. The dataset is divided into command-based speech (e.g., smart home commands) and free-form speech (e.g., casual conversations and dictation)
The system improves speech recognition through a three-step adaptation process, making it more accurate for each user over time.
To handle speech variability, the system detects stuttering, mispronunciations, and irregular pacing, adjusting in real time. It recognizes structured voice commands (e.g., "Turn on the lights") and free-form dictation (e.g., conversations and note-taking), ensuring smoother and more natural communication for each user.
The system prioritizes data privacy and security by balancing on-device processing for real-time command recognition and cloud-based models for free-form speech transcription, ensuring efficient performance while protecting sensitive user data.
Data protection measures include PII filtering to automatically remove personal identifiers before processing, explicit user consent mechanisms for data collection and sharing, and regular compliance audits to meet legal and ethical standards. Cloud-based processing is designed with encryption and restricted access controls, ensuring that sensitive speech data remains secure throughout the recognition process.
The system combines on-device and cloud-based processing to balance speed, accuracy, and data privacy. On-device processing handles real-time commands and keyword detection, keeping data private and reducing delays. Cloud-based processing manages complex, free-form speech transcription, improving accuracy while optimizing system performance and costs.
To protect user data, the system automatically removes personal information (PII) before processing. Users have full control over data collection, storage, and sharing through clear consent settings. Regular security audits ensure compliance with privacy laws and ethical AI practices, keeping data safe and usage transparent.
To improve speech recognition for users with impairments, the system incorporates voice cloning and synthetic speech generation to enhance training datasets and refine model accuracy.
This architecture ensures scalable, accurate, and privacy-compliant speech recognition tailored for users with speech impairments while continuously improving through adaptive learning.


