Large data volumes are revolutionizing industries, including medical research. This influx of data enables observational studies that harness global statistical evidence. However, conducting such studies can be labor-intensive and prone to inconsistencies due to disconnected communication channels, like repositories, emails, forums, and chats. Moreover, adapting code to different environments during the execution phase can create unscalable and non-reusable analytical frameworks. In response, the OHDSI community is developing ARACHNE, an innovative platform designed to streamline observational research by fostering collaboration among life sciences, healthcare, academia, and organizations handling patient-level data.
Challenge
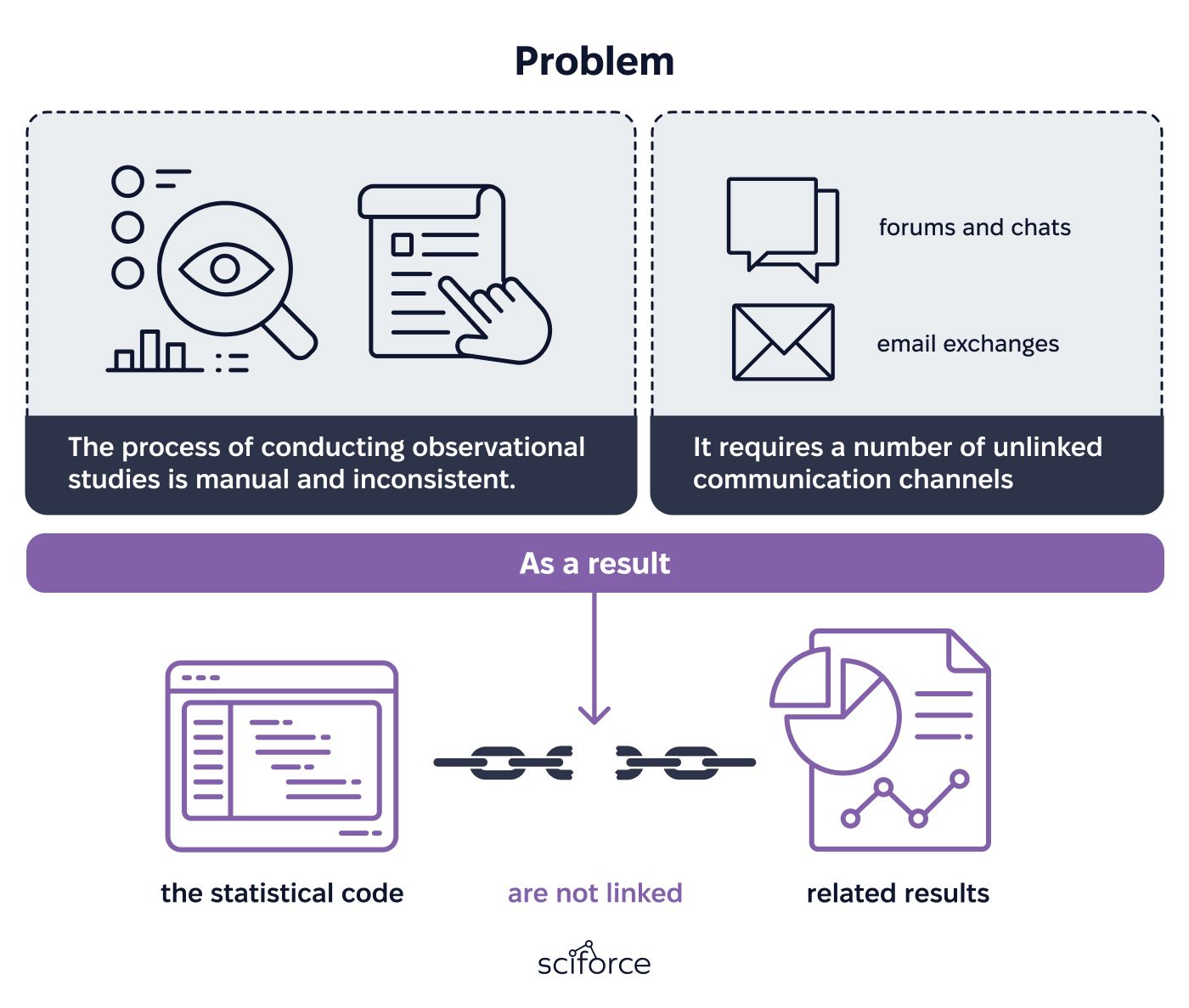
As a partner in several projects with OHDSI, our team played an instrumental role in the development of the Arachne Collaboration Network, a platform designed to facilitate the execution of federated observational studies, also known as Real-World Evidence. Sciforce's contributions included shaping the platform's architecture, overseeing both backend and frontend programming, and implementing fundamental DevOps practices.
Solution
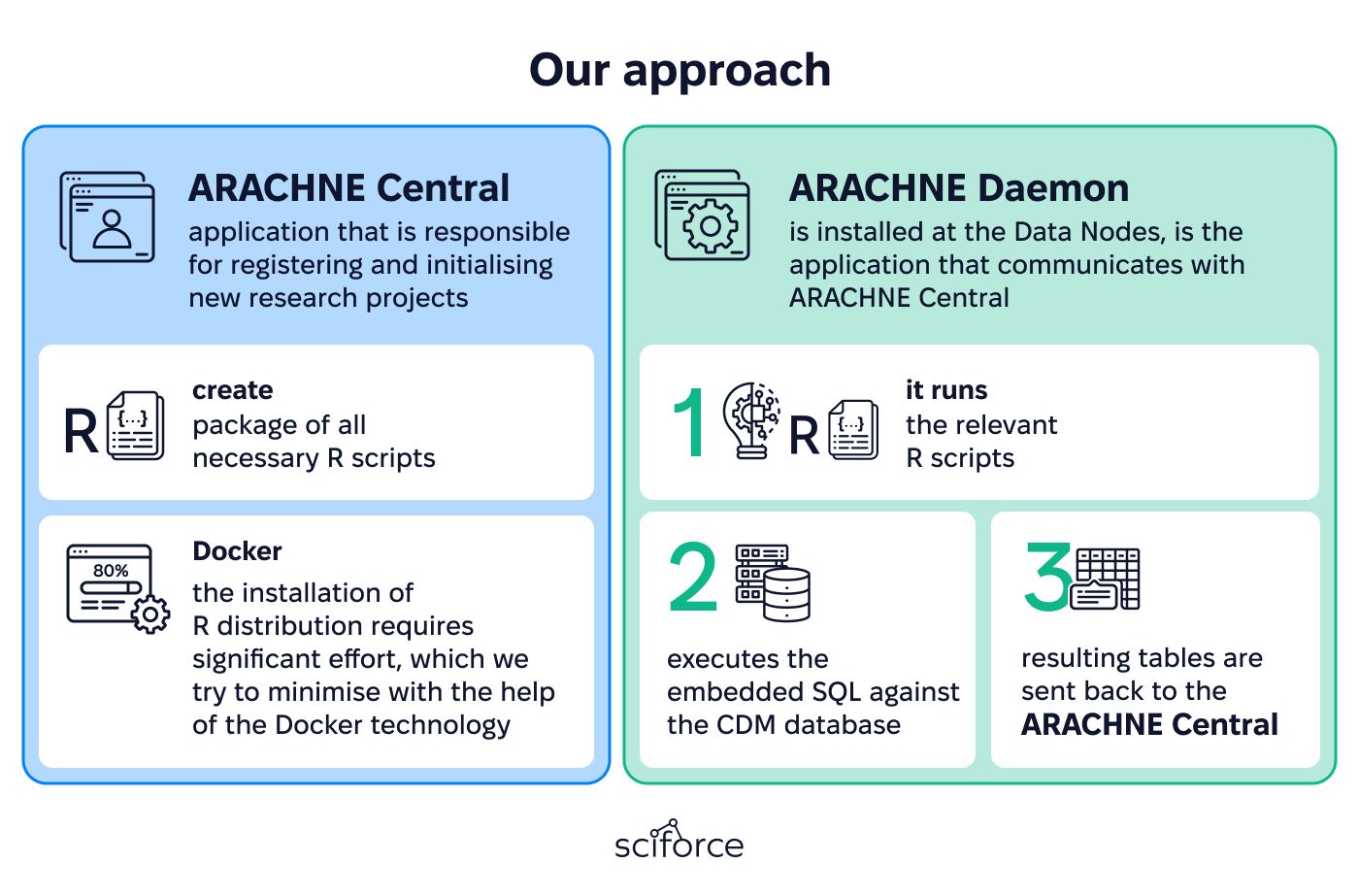
We assumed that ARACHNE should automate evidence generation through distributed research studies. Our implementation is divided into two software applications:
ARACHNE Central
- Registers and initializes new research projects.
- Creates packages with necessary R scripts for each project.
- Uses Docker to simplify R distribution installation by wrapping software with all necessary components, ensuring smooth execution regardless of environment.
ARACHNE Daemon
- Installed at Data Nodes, communicates with ARACHNE Central.
- Runs relevant R scripts and executes embedded SQL against the CDM database.
- Sends resulting tables back to ARACHNE Central.
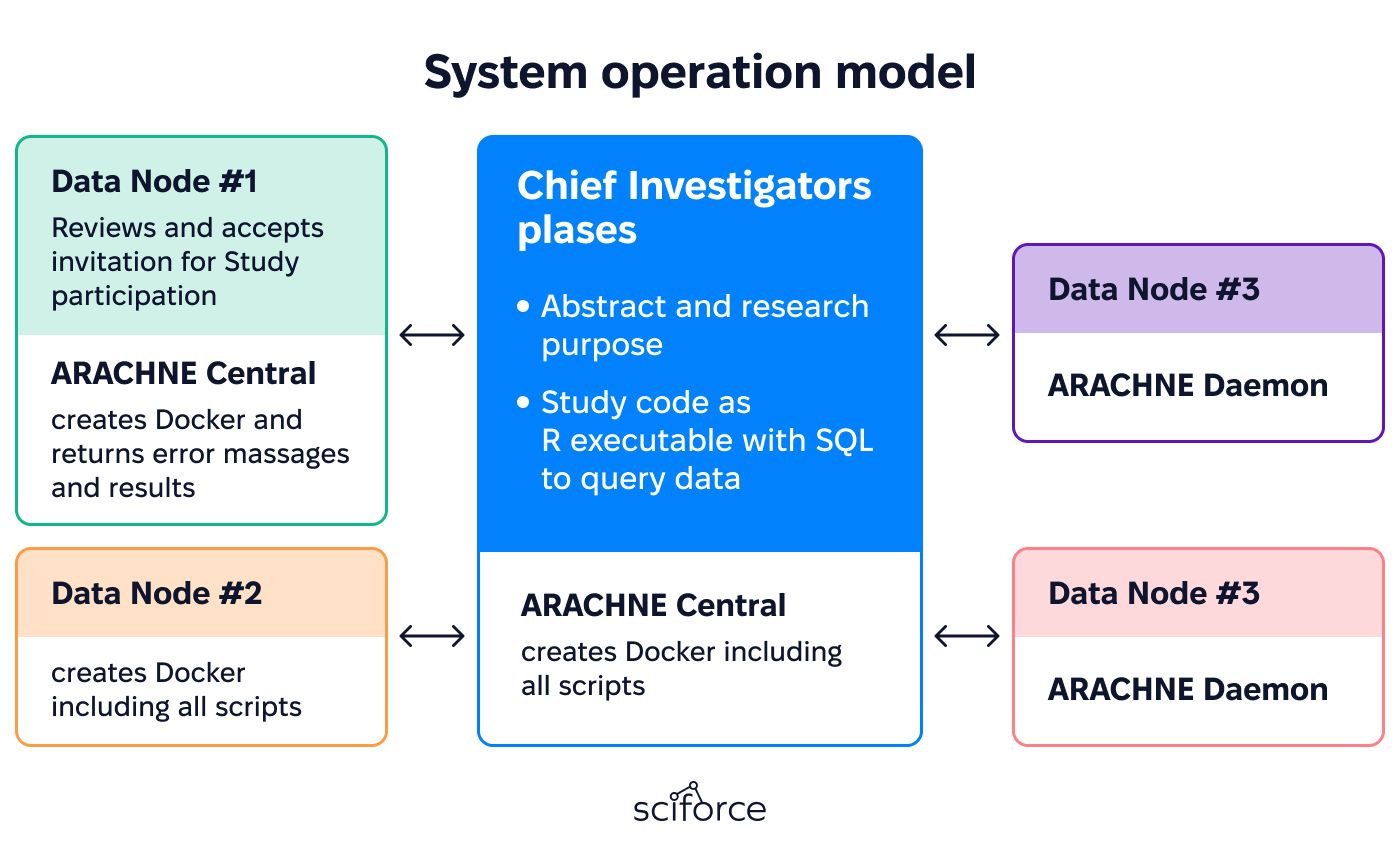
Development Journey
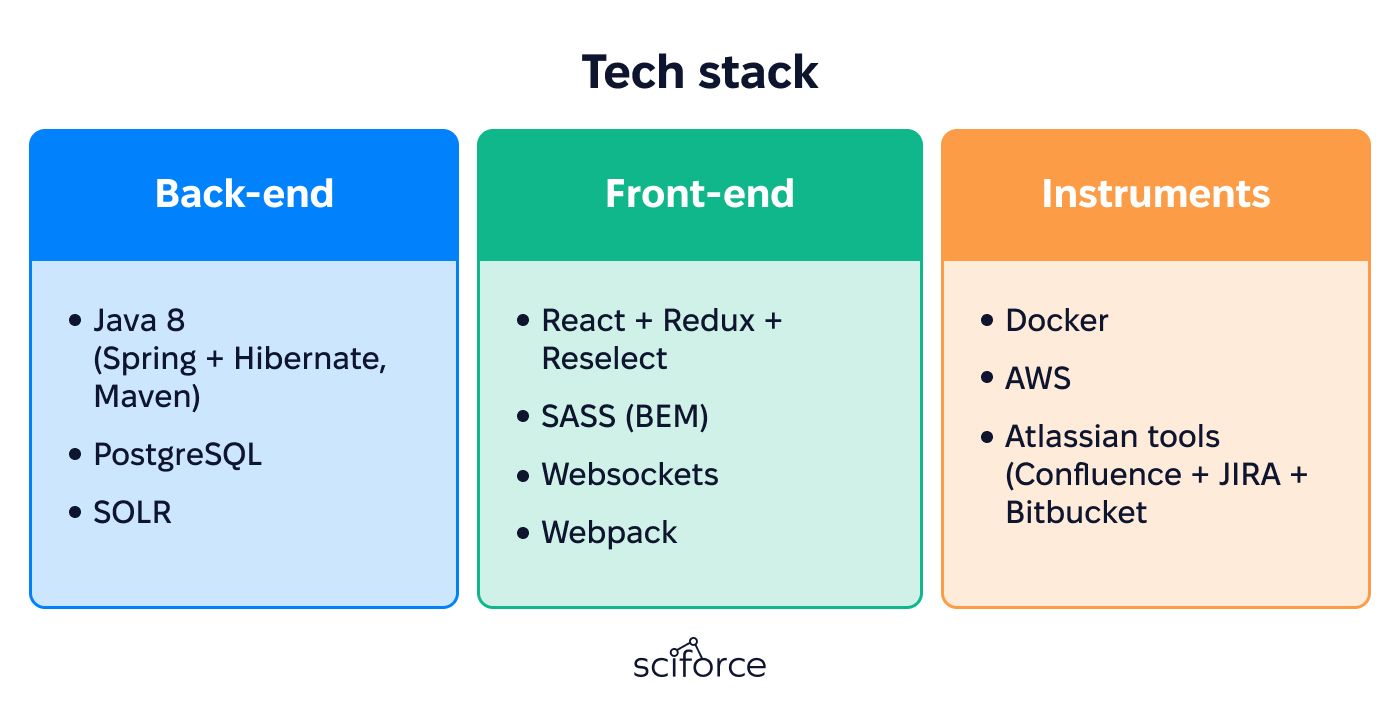
Back-end
- Language: Java 8
- Framework: Spring (used Boot for auto deployment and Security for authorization/access management)
- ORM: Hibernate (simplifies data access with object-relational mapping)
- Database: PostgreSQL (for user data)
- Search Engine: SOLR (for advanced search capabilities)
- Build Tool: Maven (for dependency management and project build)
Front-end
- Libraries: React + Redux + Reselect
- Styling: SASS (using BEM methodology)
- Communication: Websockets (for real-time data transfer)
- Bundling: Webpack (for module bundling and asset optimization)
Tools
- Containerization: Docker (for R script isolation and ease of deployment)
- Cloud: AWS (for scalable infrastructure)
- Project Management: Atlassian tools (Confluence for documentation, JIRA for task tracking, Bitbucket for version control)
Data Storage
- Big Data: Apache Cassandra (for storing research results)
Impact
We built the main part of the front-end app and its user interface, along with a file storage system. We also added features for faster communication and organized data indexing and multi-user support. Our work helped create a user-friendly tool that makes research more straightforward, transparent, and secure. It connects everyone involved in the research process, from those providing data to the people analyzing it, for a smooth end-to-end study.



