
The client is a company in the manufacturing industry that provides advanced technology solutions to improve and simplify production processes. They needed a sophisticated system to manage various types of documents, such as spec sheets, technical manuals, and product datasheets. The client's request was as follows:
- Data Management System:
The client required a robust system capable of efficiently handling and organizing various forms of documentation.
- Integrating Advanced Technologies:
They sought to leverage Natural Language Processing (NLP) and Machine Learning (ML) to automate data extraction and enhance accuracy.
- Consistency Across Formats:
The system needed to process and extract data consistently from documents with different formats and structures.
- Error Reduction:
The client aimed to reduce manual data entry errors and ensure the reliability of extracted data.
Our task was to automatically extract data fields from spec sheets that presented several complexities:
1. Multiple Model Numbers with Shared Details
Each spec sheet often contained information about multiple product models. These models shared certain details, while other details varied, typically presented in a table format. This required our system to accurately distinguish and associate the correct details with each model.
2. Heterogeneous Data from OCR
The spec sheets were processed using Optical Character Recognition (OCR) services, which, while useful, introduced inconsistencies. OCR-generated data often included errors in text recognition and formatting issues. The variability in data quality made it difficult to apply a uniform extraction approach.
3. Semi-Structured Document Formats
The spec sheets were semi-structured, meaning they contained both structured elements (like tables) and unstructured text. The tables detailing differences between models were not always clearly defined or consistently formatted, further complicating the extraction process.
4. Complex Table Structures
The tables in the spec sheets varied in complexity, with some including nested information, merged cells, or irregular layouts. These variations made it challenging to parse and extract relevant data accurately.
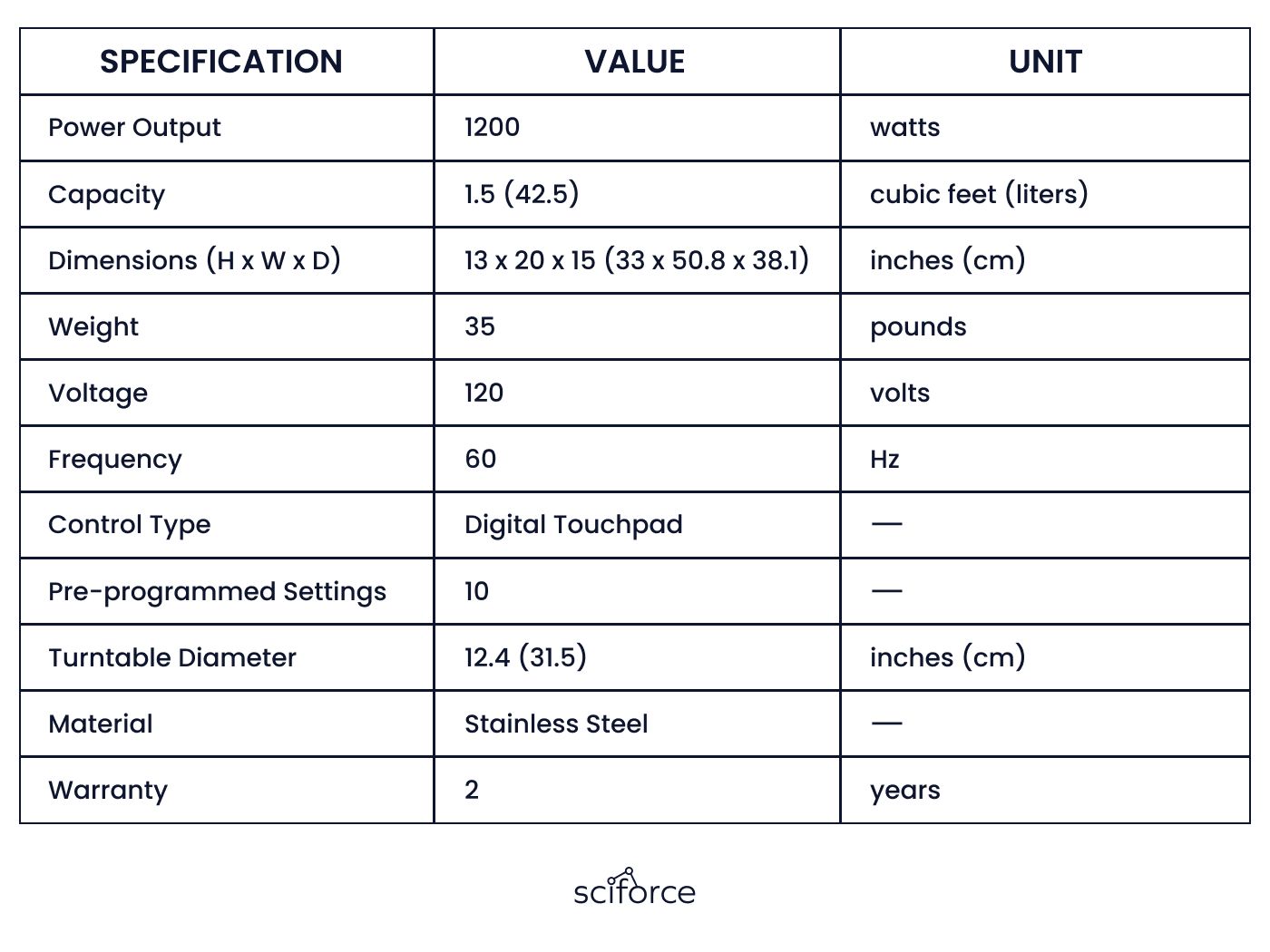
5. Manual Data Entry and Verification
While some clients provided manually filled data to guide the extraction process, the variability in manual entries and the need for precise matching with the spec sheets added another layer of complexity.
6. Field and Unit Identification
Identifying and extracting specific fields and their corresponding units of measurement required sophisticated techniques to ensure accuracy, especially when dealing with non-standardized terminology and formats.

To address the challenge of extracting data fields from semi-structured spec sheets, we developed a dual-approach solution tailored to the client's needs. This involved creating two distinct pipelines to handle different scenarios of data availability:
1. Manual Data Matching
For scenarios where the client provides specific texts and categories that need to be extracted, we developed a detailed script designed to accurately match manually filled text with corresponding locations in the spec sheet. The process includes:
Precise Matching:
The script takes a PDF document and manually filled data as input. It matches the manually entered specification parameters, values, and model names with their corresponding locations in the spec sheet.
Output Details:
The script outputs bounding boxes and page numbers for each manually filled entry. This ensures that each piece of data is precisely located within the document, allowing for easy verification and further processing.
2. Automatic Spec Category Filling
For scenarios where the client provides only the expected spec categories, we developed a comprehensive script to automatically populate the values and units of measurement for each spec category. The process involves:
Automated Filling:
The script takes a PDF document and a list of expected spec categories as input. It automatically identifies and fills in the relevant spec values and units of measurement.
Output Details:
The script outputs bounding boxes, page numbers, spec values, and units of measurement for each spec category. If the script's confidence level is low, it outputs several candidates for human review to ensure accuracy;
1. Text Extraction
Begins with custom OCR to accurately extract text along with bounding boxes from scanned documents, converting scanned images into machine-readable formats. For text-based documents, a PDF reader directly reads and extracts text and bounding boxes, ensuring precise text location mapping.
2. Candidate Matching
It involves identifying potential matches for manually filled data points, such as specification parameter names, values, and model names, with text extracted from the OCR process. Algorithms like Levenstein distance, Jaccard similarity, and cosine similarity measure the similarity between manually filled data and OCR-extracted text, ranking candidates based on similarity scores to select the best matches.
3. Clustering
This is a crucial step where numbers, units of measurements, names of categories, and their synonyms are extracted from the OCR output. The OCR output is then post-processed to create an index of words and their corresponding bounding boxes.
Clustering algorithms such as Chinese whispers construct a graph where nodes represent words and edges represent distances between bounding boxes, clustering words based on proximity. Predefined pixel ranges assign ranges around each word, identifying clusters with the most neighbors as cluster centers. Small or irrelevant clusters are eliminated to focus on meaningful groups related to spec categories.
4. Periodicity Exploitation
Periodicity exploitation analyzes periodic structures within the document to identify repeating patterns. By calculating distances between clusters and finding pairs with similar relative distances, the system can determine associations and group clusters based on identified periodic patterns and calculated distances, ensuring accurate association of data with specific products.
5. Spec Extraction
Here we identify clusters that are likely to contain necessary specs and extract the relevant information. The extraction methods are adjusted to handle complex table structures within the documents, and text patterns like number x number x number are utilized to identify and extract product dimensions.
6. Anomaly Detection
Anomaly detection further enhances accuracy by extracting important words for each document to improve clustering accuracy and generating distributions of spec values to detect anomalies. This step increases data accuracy by comparing extracted product specs across documents to enhance the overall quality and reliability of the data.
Initial Stage
1. Requirement Analysis
Collaborated with the client to understand the specific requirements, including the types of documents, the data to be extracted, and the expected output formats.
2. Design
Created the architecture for two distinct approaches (Plan A and Plan B) to handle the different scenarios of data availability.
Intermediate Stage
3. Custom OCR Development
Developed a custom OCR solution tailored to the specific needs of scanned documents, ensuring accurate text extraction with bounding boxes.
4. Algorithm Development
Designed and implemented algorithms for text extraction, candidate selection, and ranking for Plan A, and for location finding, clustering, and spec extraction for Plan B.
5. Pipeline Integration
Integrated the OCR and algorithms into a cohesive pipeline that could process the spec sheets end-to-end.
Final Stage
6. Testing and Validation
Conducted extensive testing on a variety of spec sheets to validate the accuracy and reliability of both approaches. Adjusted algorithms and refined processes based on feedback and observed performance.
7. Optimization
Optimized the system for performance and scalability, ensuring it could handle large volumes of documents efficiently.
8. Deployment
Deployed the solution on the client’s infrastructure, providing training and support to ensure smooth adoption and integration into their existing workflows.
How it works
Scenario A
For scenarios where the client provides specific texts and categories that need to be extracted, we developed a detailed script designed to accurately match manually filled text with corresponding locations in the spec sheet:
1. Text Extraction
For scanned documents, we use custom OCR to extract text along with their bounding boxes. For text-based documents, a PDF reader is utilized to directly read and extract text and bounding boxes.
2. Candidate Selection
Identifying potential matches for manually filled data points, such as specification parameter names, values, and model names, with the text extracted from the OCR process. Each manually filled data point is then associated with its corresponding bounding box extracted from the OCR.
3. Candidate Ranking
The candidate ranking process uses the Levenstein distance algorithm to calculate the similarity between the manually filled data and the OCR-extracted text. To ensure the most accurate matches, additional ranking methods, such as Jaccard similarity and cosine similarity, are implemented.
Finally, we rank the identified candidates based on their similarity scores and select the best possible match for each manually filled entry.
Scenario B
For scenarios where the client provides only the expected spec categories, we developed a comprehensive script to automatically populate the values and units of measurement for each spec category. The process involves:
1. Text Extraction
The same as in Scenario A: custom OCR for extracting the information from scanned documents or a PDF reader to read the document directly.
2. Location Finding and Clustering:
Numbers, units of measurements, names of categories, and their synonyms are extracted from the OCR output. This output is post-processed to create an index of words and bounding boxes. WordNet is used to find related terms. Clustering algorithms, like Chinese whispers or predefined pixel ranges, group related data points.
Chinese whispers constructs a graph to cluster words based on proximity, while predefined pixel ranges identify clusters by assigning ranges around each word. Small or irrelevant clusters are eliminated to focus on meaningful groups related to the spec categories.
3. Cluster Association
We start with exploiting the periodicity of the document structure to find a period in the number of lines of text (or pixels).
We collect distances between clusters by searching for pairs of element pairs with similar relative distances (e.g. for elements A, B, C, D with distance A-B similar to distance C-D). Then we extract a period by averaging distance A-C across all pairs of pairs. One period contains data about one product.
It’s possible to group clusters by the obtained periods and return results. To enhance results, we similarly exploit periodicity in types of words (numbers, units of measurement, or spec categories).
4. Spec Extraction:
As a first step, we search for a number, a unit of measurement, or the spec category within the same cluster or its neighbor clusters. If possible, we detect if the cluster is a table and change the extraction algorithm for it.
To enhance the extraction quality, we compare the product specs to other products in the document. We use patterns in the text such as number x number x number as a common pattern for dimensions of the product.
Enhanced Efficiency:
The automated system reduced the time required to process spec sheets by 70%, allowing for faster data availability and decision-making. The need for manual data entry was significantly diminished, freeing up human resources for more strategic tasks and increasing overall productivity by 50%.
Improved Accuracy:
The custom OCR and advanced text extraction techniques achieved an accuracy rate of 95%, significantly reducing errors associated with manual data entry. The implementation of candidate ranking algorithms, including Levenstein distance, Jaccard similarity, and cosine similarity, ensured the most accurate matches for manually filled data, reducing data entry errors by 80%.
Scalability:
The solution is capable of processing up to 10,000 spec sheets per month without compromising performance, meeting the growing data processing needs of the client.
Cost Savings:
By automating the data extraction process, the client experienced a 60% reduction in labor costs and a 50% reduction in error rectification costs. The efficient processing pipeline decreased operational costs associated with delayed data processing by 40%.
Client-Specific Benefits:
The client reported a 70% reduction in manual data entry errors and a 60% faster processing time. The ability to handle heterogeneous and semi-structured data formats expanded the client’s capability to manage diverse document types, enhancing their overall data management strategy.
We used advanced Natural Language Processing (NLP) and Machine Learning (ML) to automate the extraction of detailed specifications and measurements from complex product spec sheets for the manufacturing company.
