
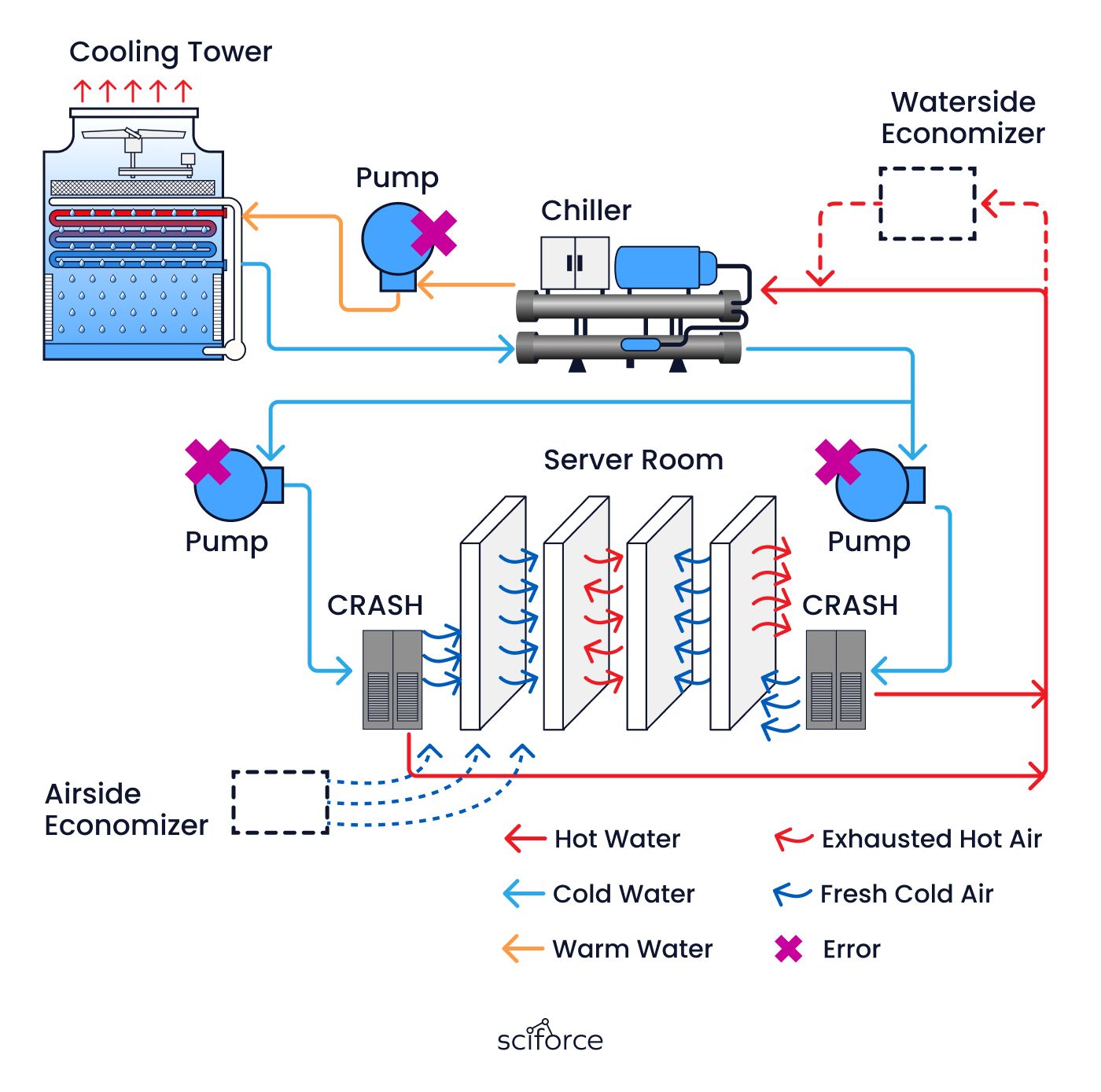
Our client is a leading technology company specializing in large-scale data centers for enterprise customers in finance, healthcare, and e-commerce. They manage high-density server environments where efficient cooling is critical to prevent hardware failures.
The client had a recurring problem in their data centers: a critical pump in their cooling systems kept failing unexpectedly, causing major disruptions. Despite regular inspections, they couldn’t figure out why the pump was breaking, as they only discovered the issue after it had already failed. This reactive approach led to costly unplanned downtime, which the client wanted to avoid. Our task was to create a solution that could predict and prevent these pump failures.
1. Incomplete or Unlabeled Dataset
We initially believed the client had a labeled dataset that could be used directly to train a predictive model. However, it turned out that the data lacked labels, meaning we couldn’t identify when and where failures had occurred. This forced us to shift our strategy to focus on anomaly detection and correlation analysis to uncover patterns in the data without predefined labels.
2. Data Complexity
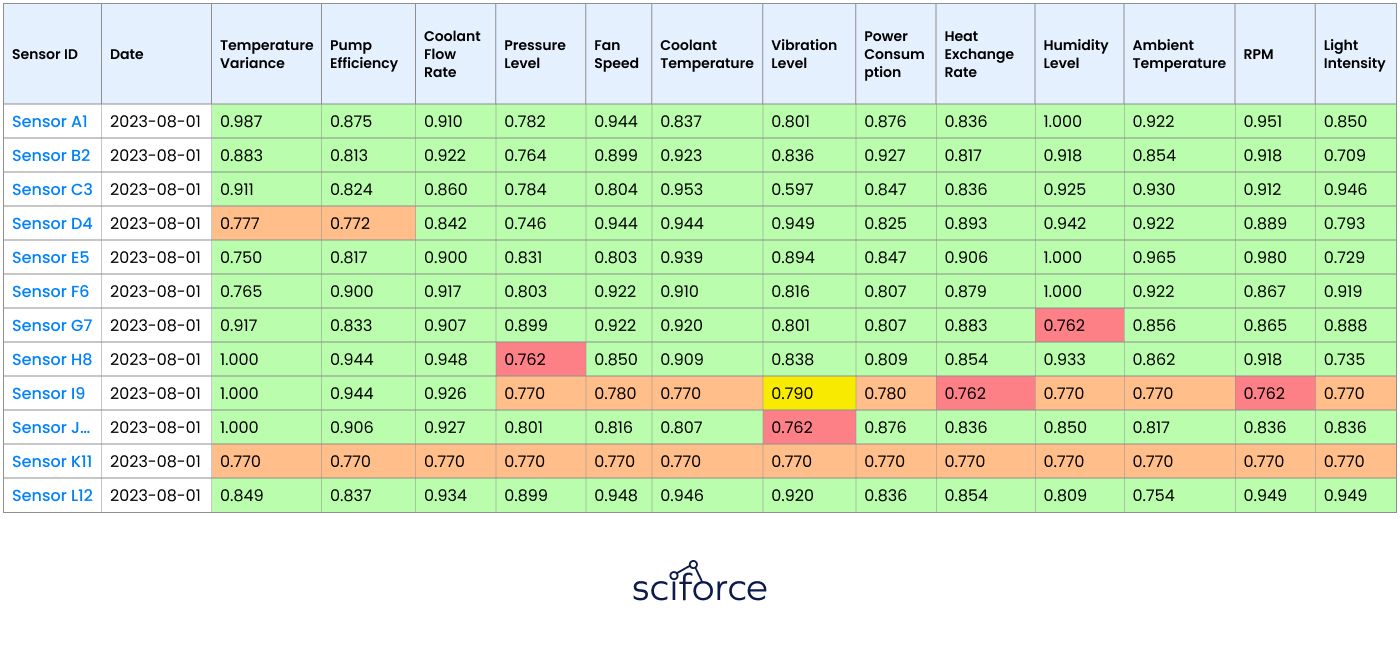
The dataset contained sensor readings from over 100 different parameters, all related to the cooling system’s operation. Analyzing this vast and varied data to identify anomalies linked to pump failures was a challenging task that required detailed data processing and sophisticated analysis techniques.
3. Validation Constraints
Without specific confirmation from a domain expert, we relied on data-driven methods to validate the anomalies and their connection to the pump failures. While this approach allowed us to identify patterns, it added complexity in ensuring that the detected anomalies were accurately aligned with the root cause of the issues.
4. Shifting Project Scope
The project’s focus shifted from simply training a model to a more complex process that included extensive data cleaning, anomaly detection, and correlation analysis. This change required us to quickly adapt our development approach to handle the new challenges effectively.
5. Ensuring Anomaly Detection Reliability
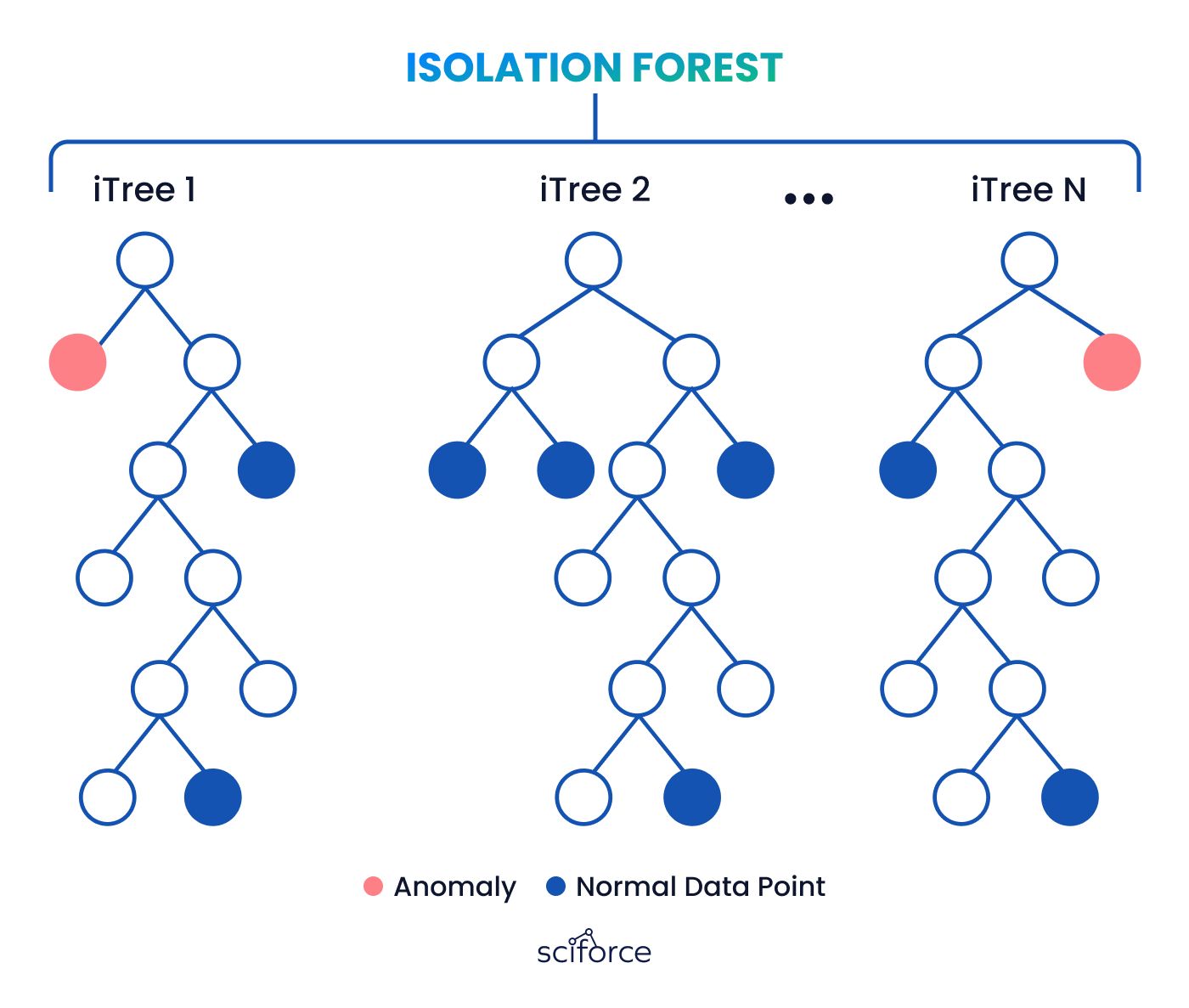
To ensure our anomaly detection was accurate, we used multiple algorithms, such as Isolation Forest, and employed a majority voting system to validate the results. This approach added complexity but was necessary to increase the reliability of our findings and ensure the anomalies identified were indeed significant.
We developed a system designed to predict and prevent failures in the client’s cooling systems, specifically addressing a recurring issue with a particular pump. The system continuously monitors sensor data in real-time to detect any anomalies that could indicate a potential failure. By identifying these anomalies early, the system alerts the maintenance team, allowing them to intervene before the issue leads to equipment breakdowns and costly downtime.
Lack of Labeled Data:
The client did not have a labeled dataset that could be used to train a traditional predictive model.
Anomaly Detection Approach:
We leveraged advanced algorithms, such as Isolation Forest, to identify anomalies in the sensor data.
Correlation with Failures:
Sensors that correlated most strongly with the anomaly label were then identified as most likely to be associated with the breakdown.
Proactive Monitoring:
This approach allowed us to continuously monitor these critical indicators and provide early warnings, aligning with the client's need for a proactive maintenance solution.
We initially considered building a machine learning model using a labeled dataset. Upon discovering the lack of labeled data, we pivoted to using anomaly detection combined with correlation analysis. It finally provided the most reliable and actionable results within the constraints of the existing data, without the need for extensive additional data collection or labeling.
1. Data Collection
We explored several anomaly detection algorithms, including Isolation Forest, to monitor data from over 100 sensors in real-time. These algorithms helped spot unusual patterns or changes in key parameters like temperature, pressure, and flow rate. By using multiple algorithms and a majority voting system, we improved the accuracy of detecting potential issues with the pump or other parts of the cooling system.
2. Identifying Anomalies
Using advanced anomaly detection algorithms such as Isolation Forest, we analyzed the sensor data to detect unusual patterns or deviations that could indicate potential issues. We employed multiple algorithms and used a majority voting system, marking the issue as anomaly, if the majority of the algorithm detected it so.
3. Correlation with Failures
Analyzed the detected anomalies around the known pump replacement dates. This helped us identify specific sensor patterns that were consistently present before a failure.
4. Isolating Critical Sensors
Through the correlation analysis, we pinpointed a subset of sensors that displayed anomalies before the pump change date. Focusing on these critical sensors reduced complexity and improved monitoring efficiency.
5. Developing an Early Warning System
Based on the insights gained, we proposed developing a real-time monitoring system that continuously analyzes incoming sensor data for similar anomaly patterns. When such patterns are detected, the system would issue early warnings to the maintenance team, enabling proactive interventions to prevent failures.
6. Future Model Training
With further data collection and labeling based on these anomalies and outcomes, it is possible to create a hybrid approach in the form of sequential use. Anomaly detection would serve as a first-level filter. Once an anomaly is detected, a more complex model like an trained LSTM neural network can analyze the flagged data to predict the likelihood of a breakdown.
1. Initial Assessment and Problem Understanding
Client’s Challenge:
The client experienced recurring failures with a specific pump in their cooling systems. Despite regular maintenance, the pump failures were only identified after they had already occurred, causing unexpected downtimes and operational disruptions. The client lacked a labeled dataset, making it difficult to train a traditional predictive model.
Objective:
Develop a system that could predict and prevent these failures by monitoring sensor data in real-time, identifying anomalies, and providing early warnings to the maintenance team.
2. Data Exploration and Preparation
Data Collection:
The initial dataset comprised sensor readings from over 100 different parameters related to the cooling systems. These sensors monitored various aspects, including temperature, pressure, and flow rates.
Data Challenges:
The dataset was not labeled, and the client lacked specific expertise to validate the correlation between sensor data and pump failures.
3. Anomaly Detection Implementation
Algorithm Selection:
We chose advanced anomaly detection algorithms, such as Isolation Forest, to identify unusual patterns in the sensor data that could indicate potential issues.
Majority Voting System:
To improve the reliability of anomaly detection, multiple algorithms were employed. Anomalies were flagged only when detected by a majority of the algorithms, reducing the risk of false positives.
Correlation Analysis:
Through the correlation analysis, we pinpointed a subset of sensors that displayed anomalies specifically before the pump replacement date. By focusing on these critical sensors, which showed a correlation between the identified anomalies and the sensor readings, we reduced complexity and improved monitoring efficiency.
4. Isolating Critical Sensors
Sensor Identification:
Through correlation analysis, we identified a subset of sensors whose anomalous readings were strongly associated with the pump failures. Focusing on these critical sensors allowed us to streamline the monitoring process and reduce the complexity of the system.
Data Labeling:
The identified anomalies and their correlations with pump failures enabled us to label critical points in the dataset. This labeled data was crucial for any future model training.
5. Proposing the Early Warning System
System Design:
Based on the identified patterns, we proposed a real-time monitoring system that would continuously analyze sensor data for similar anomaly patterns. The system was integrated with an alert mechanism that triggers warnings when the model detects significant likelihood of anomalies, allowing the maintenance team to take proactive measures before a failure occurs.
Scalability Considerations:
The system was designed with scalability in mind, enabling it to adapt to additional sensors and potential expansions of the client’s infrastructure.
Using advanced anomaly detection algorithms like Isolation Forest, we identified anomalies in the sensor data that were consistently correlated with pump failures. This process allowed us to isolate 4 critical sensors that were directly linked to the issue. As a result, we reduced the false alarm rate by 30% and improved the detection accuracy by 40%, enabling the maintenance team to receive more precise and timely alerts.
With the identified sensors now being closely monitored, the client experienced a 25% reduction in unplanned downtime related to the pump failures. Additionally, the maintenance team's response time improved by 20%, as they were able to address potential issues before they escalated into full-scale failures.
The solution brought clear and measurable benefits, including a 30% drop in false alarms, a 40% boost in detection accuracy, and a 25% cut in unplanned downtime. These results highlighted the effectiveness of using anomaly detection for predictive maintenance and set the client up for even better operational reliability as they continue to improve and expand the system.
Anomaly detection helped our client to spot early signs of potential pump issues, allowing them to prevent failures before they occurred and avoid costly downtime. Let's implement proactive maintenance in your manufacturing infrastructure? Book a free consultation to explore the possibilities.
