Automatic speech recognition (ASR) systems are becoming an increasingly important part of human-machine interaction. Simultaneously, they are still too expensive to develop from scratch. Companies need to choose between using a cloud API for an ASR system developed by tech giants or playing with open-source solutions.
In this post, we compare eight of the most popular ASR systems to facilitate the choice for your project needs and team’s skills. We have conducted our tests to define the word error rate (WER) for some listed ASR systems. We promise to update and add any new info when possible. Let’s dive right into it.
Automatic speech recognition (ASR) is a technology identifying and processing human voice with the help of computer hardware and software-based techniques. You can use it to determine the words spoken or authenticate the person’s identity. In recent years, ASR has become popular across industries in the customer service departments.
Basic ASR systems recognize isolated-word entries such as yes-or-no responses and spoken numerals. However, more sophisticated ASR systems support continuous speech and allow entering direct queries or replies, such as a request for driving directions or the telephone number of a specific contact. The state-of-the-art ASR systems recognize wholly spontaneous speech that is natural, unrehearsed, and contains minor errors or hesitation markers.
However, commercial systems offer little access to detailed model outputs, including attention matrices, probabilities of individual words or symbols, or intermediate layers outputs, and limited integrability into other software.
Hence, ASR systems like AT&T Watson, Microsoft Azure Speech Service, Google Speech API, and Nuance Recognizer (bought by Microsoft in April 2021) are not that much flexible.
In response to these limitations, more open-source ASR systems and frameworks enter the picture. However, the growing number of such systems makes it challenging to understand which of them suits the project’s needs best, which offers complete control over the process, which can be used without too much effort and deep knowledge of Machine and Deep Learning. So, let’s reveal all the nuts and bolts.
Of course, commercial ASR systems developed by such tech giants as Google or Microsoft offer the best accuracy in speech recognition. On the downside, they seldom provide developers much control over the system, usually allowing them to expand vocabulary or pronunciation but leaving the algorithms untouched.
Google Cloud Speech-to-Text is a service powered by deep learning neural networking and designed for voice search or speech transcription applications. Currently, it is the clear leader among other ASR services in terms of accuracy and the languages covered.
Language support
Currently, the system recognizes 137 languages and variants with an extensive vocabulary in default, common, and search recognition models. You can use the default model to transcribe any audio type while using search and command ones for short audio clips only.
Input
It is possible to directly stream sound files that are less than a minute long to perform the so-called synchronous speech recognition when you talk to your phone and get a text back. The proper way to do it is to upload it to Google Storage and use the asynchronous API for longer files.
Supported audio encodings are MP3, FLAC, LINEAR16, MULAW, AMR, AMR_WB, OGG_OPUS, SPEEX_WITH_HEADER_BYTE, WEBM_OPUS.
Pricing
Google provides one free hour of audio processing and $1,44 per hour of audio.
Pricing for Google Cloud Speech-to-Text.(Image credit: Google)
Models
Google offers four pre-built models: default, voice commands and search, phone calls, and video transcription. The Standard model is best suited for general use, like single-speaker long-form audio, while the Video model is better at transcribing multiple speakers (and videos). In reality, the newest and more expensive Video model performs better in all settings.
Selecting models for Google Cloud Speech-to-Text.(Image credit: Google)
Customization
A user can customize the number of hypotheses returned by the ASR, specify the language of the audio file and enable a filter to remove profanities from the output text. Moreover, speech recognition can be customized to a specific context by adding the so-called hints — a set of words and phrases that are likely to be spoken, such as custom words and names, to the vocabulary and in voice-control use cases.
Accuracy
Franck Dernoncourt reported that Google’s WER of 12,1% (LibriSpeech clean dataset). We also have tested Google Cloud Speech on the LibriSpeech dataset sample and got the WER for male and female clear voice 17,8% and 18,8% correspondingly, while 32,5% and 25,3% for noisy environments correspondingly.
The cloud-based Microsoft Azure Speech Services API helps create speech-enabled features in applications, like voice command control, user dialog using natural speech conversation, and speech transcription and dictation. The Speech API is part of Cognitive Services (previously Project Oxford). In its basic REST API model, it doesn’t support intermediate results during recognition.
Language support
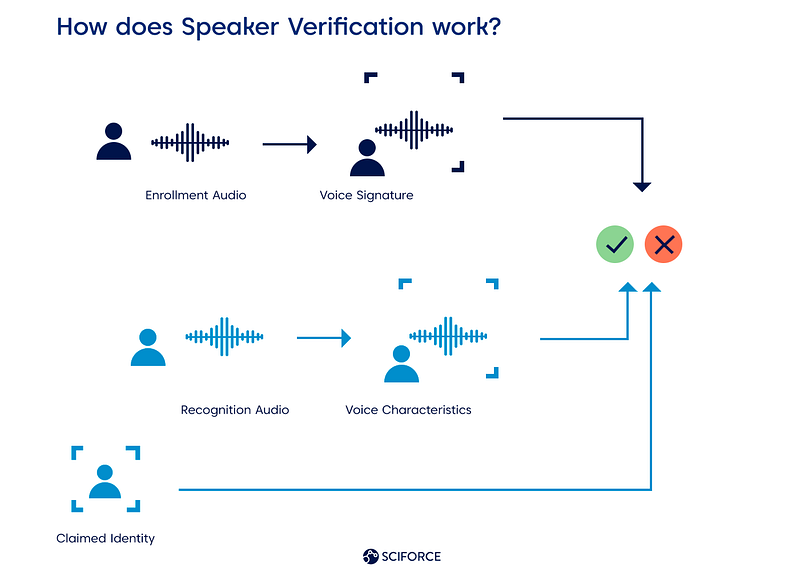
Microsoft’s speech-to-text service supports 95 languages and regional variations, text-to-speech service support 137 ones. Speech-to-speech and speech-to-text translation services support 71 languages. Speaker recognition, a service that verifies and identifies the speaker by their voice characteristics, is available in 13 languages
Input
The REST API supports audio streams up to 60 seconds, and you can use it for online transcription as a replacement of the Speech SDK. For longer audio files, you should use the Speech SDK or Speech-to-text REST API v3.0.
Using the Speech SDK, consider that the default audio streaming format is WAV (16 kHz or 8 kHz, 16-bit), other formats are also supported with GStreamer: MP3, OPUS/OGG, FLAC, ALAW in wav container, MULAW in wav container, ANY (using for the scenario with an unknown media format).
Pricing
Speech to Text — $1 per hour
Speech to Text with Custom Speech Model — $1.40 per hour
There is a free version for one concurrent request with the threshold of 5 hours per month. For more detailed plans, check out pricing page here.
Interfaces
Microsoft provides two ways for developers to add the Speech Services API to their apps:
Customization
The Speech service allows users to adapt baseline models based on their acoustic and language data, customizing their vocabulary and acoustic models and pronunciation.
The diagram presents the features of the Custom Speech by Azure. Source
Accuracy
Franck Dernoncourt reported that Azure’s WER of 18,8% (LibriSpeech clean dataset). We also have tested Microsoft’s speech-to-text service on the LibriSpeech dataset sample and got the WER for male and female clear voice 11,7% and 13,5% correspondingly, while 26% and 21,3% for noisy environments correspondingly.
Amazon Transcribe is an automatic speech recognition system that, above all, adds punctuation and formatting by default so that the output is more intelligible, and you can use it without any further editing.
Language support
At present, Amazon Transcribe supports 31 languages, including regional variations of English and French.
Input
Amazon Transcribe supports both 16 kHz and 8kHz audio streams and multiple audio encoding, including WAV, MP3, MP4, and FLAC with time stamps for every word so that it is possible, as Amazon claims on its website, to “easily locate the audio in the original source by searching for the text.” The service calls are limited to two hours per API call.
Pricing
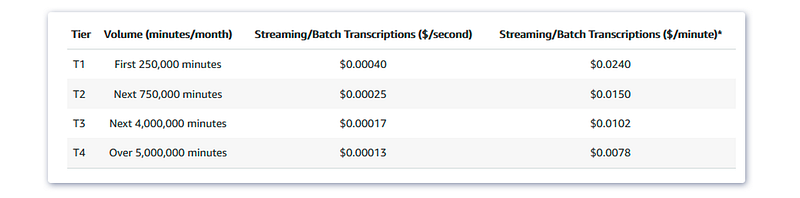
Amazon’s pricing is based on the pay-as-you-go of audio transcriber per month, starting from $0,0004 per second for the first 250,000 minutes.
A free tier is available for 12 months with a limit of 60 minutes per month.
All the pricing details available on Amazon’s page
Customization
Amazon Transcribe allows for customized vocabularies written in the accepted format and using characters from the allowed character set for each supported language.
Accuracy
Having a limited collection of languages and only one baseline model available, Amazon Transcribe shows the WER of 22%.
Watson Speech to Text service is an ASR system that provides automatic transcription services. The system uses machine intelligence to combine information about grammar and language structure with knowledge about the composition of the audio signal to transcribe the human voice accurately. As more speech is heard, the system retroactively updates the transcription.
Language Support
The IBM Watson Speech to Text service supports 19 languages and variations.
Input
The system supports 16kHz and 8kHz audio streams in MP3, MPEG, WAV, FLAC, OUPS, and other formats.
Pricing
IBM provides you with a free plan of up to 500 minutes per month (no customization available). Users can conduct up to 100 concurrent transcriptions for $0.02 per minute for 1–999,999 minutes per month within the Plus plan. The details for other plans are available per request.
Interfaces
The Watson Speech to Text service offers three interfaces:
Customization
For a limited selection of languages, the IBM Watson Speech to Text service offers a customization interface that allows developers to augment their speech recognition capabilities. You can improve speech recognition requests’ accuracy by customizing a base model for domains such as medicine, law, information technology, and others. The system allows customization of the language and the acoustic models.
Accuracy
Franck Dernoncourt reported that Azure’s WER of 9,8% (LibriSpeech clean dataset). We also have tested Microsoft’s speech-to-text service on the LibriSpeech dataset sample and got the WER for male and female clear voice 17,4% and 19,6% correspondingly, while 37,5% and 27,4% for noisy environments correspondingly.
SpeechMatics, both cloud-based and on-premise service HQ-ed in the UK, uses recurrent neural networks and statistical language modeling. Enterprise-targeted service offers free and premium features like real-time transcriptions and audio-file upload.
Language support
They cover 31 languages. SpeechMatics promises to cope with challenges like noisy environments, different accents, and dialects.
Input
The audio and video formats that this ASR system supports are: WAV, MP3, AAC, OGG, FLAC, WMA, MPEG, AMR, CAF, MP4, MOV, WMV, MPEG, M4V, FLV, MKV. The company claims that other formats could also be supported but after the additional user acceptance test.
Pricing
As the majority of enterprise-targeted companies, SpeechMatics provides plans and pricing details on request. The company uses a volume-based strategy and provides a 14-day free trial.
Customization
This system is highly configurable — you can create your user interface tailored to your needs. There is no default UI provided, but you can have it through one partner when needed. You can add your own words to the dictionary and teach the engine how to recognize them. You also can tune up the system to exclude sensitive information or profanations. SpeechMatics also supports real-time subtitling.
Accuracy
Franck Dernoncourt tested SpeechMatics on the LibriSpeech clean test data set (English) — WER 7,3%, which is pretty good compared to other commercial ASR systems.
The variety of open-source ASR systems makes it challenging to find those that combine flexibility with an acceptable word error rate. In this post, we have selected Kaldi and HTK as popular ones across community platforms.
Kaldi was initially made for researchers, but it has made a name for itself fast. Kaldi is a Johns Hopkins University toolkit for speech recognition written in C++ and licensed under the Apache License v2.0. Famous for its results that can actually compete with and even beat Google, Kaldi is, however, challenging to master and set up to work correctly, requiring extensive customization and training on your corpus.
Languages support
Kaldi does not provide the linguistic resources required to build a recognizer in a language, but it does have a recipe to create one on your own. When you give enough data, you can train your model with Kaldi. You also can use some pre-built models on Kaldi’s page.
Input
The audio files are accepted in the WAV format.
Customization
Kaldi is a toolkit for building language and acoustic models to create ASR systems on your own. It supports linear transforms, feature-space discriminative training, deep neural networks, MMI, boosted MMI and MCE discriminative training.
Accuracy
We have tested Kaldi on the LibriSpeech dataset sample and got the WER for male and female clear voice about 28%% and 28,1% correspondingly, while about 46,7% and 40,2% for noisy environments correspondingly.
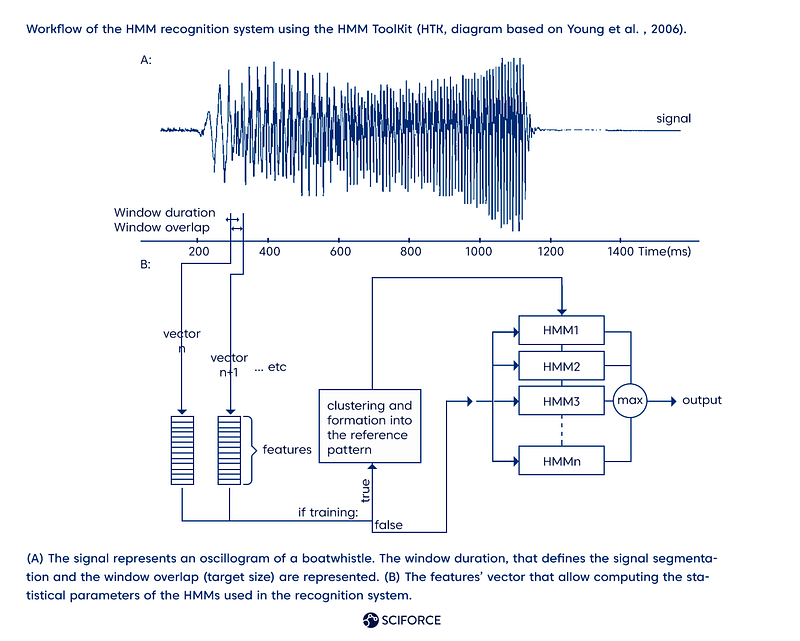
HTK, or Hidden Markov Model Toolkit, written in C programming language, was developed in the Cambridge University Engineering Department to handle HMMs. HTK focuses on speech recognition, but you can also use it for text-to-speech tasks and even DNA sequencing.
Today, Microsoft has obtained the copyright to the original HTK code but still encourages changes to the source code. Interestingly, being one of the oldest projects, it is still used extensively and has new versions released. Moreover, HTK has an insightful and detailed book called “The HTKBook” which describes both the mathematical basis of speech recognition and how to do specific actions in HTK.
Language support
Similar to Kaldi, HTK is language-independent, with the possibility to build a model for every language.
Input
By default, the speech file format is HTK, but the toolkit also supports various formats. You can set the configuration parameter SOURCEFORMAT for other formats.
Customization
Fully customizable, HTK offers training tools to estimate the parameters of a set of HMMs using training utterances and their associated transcriptions and recognition tools to transcribe unknown utterances.
Accuracy
The toolkit was evaluated using the well-known WSJ Nov ’92 database. The result was impressive at 3.2% WER, using a trigram language model on a 5000-words corpus. However, in real life, the WER reaches 25–30%.
Using any open-source ASR toolkit, the optimal way to quickly develop an ASR recognizer would be to use the open-source code to the papers that have the highest results on well-known corpora (the Facebook AI Research Automatic Speech Recognition Toolkit, a Tensorflow implementation of the LAS model, or a Tensorflow library of deep learning models and datasets, to name a few).
The technology of automatic speech recognition has been around for some time. Though the systems are improving, problems still exist. For example, an ASR system cannot always correctly recognize the input from a person who speaks with a heavy accent or dialect or speaks in several languages.
There are various tools, both commercial and open-source, to integrate ASR into the company’s applications. When choosing between them, the crucial point is to find the correct balance between the usually higher quality of proprietary systems and the flexibility of open-source toolkits.
Companies need to understand their resources as well as their business needs. If ASR is used in conventional and well-researched settings and does not require too much additional information, a ready-to-use system is the most optimal solution. On the contrary, if ASR is the project’s core, a more flexible open-source toolkit becomes a better option.